[论文解读] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL 是一个显著增强的潜在扩散模型,用于文字生成图像,具备更大的 UNet、新的条件化方案、多方面训练以及一个改进阶段,在用户偏好方面明显优于早前的 Stable Diffusion 版本,并且在 SOTA 表现上具有竞争力。
We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators. In the spirit of promoting open research and fostering transparency in large model training and evaluation, we provide access to code and model weights at https://github.com/Stability-AI/generative-models
研究动机与目标
- 提升相较于先前 Stable Diffusion 版本的文本生成图像中图像保真度与提示遵循性。
- 通过架构扩展和多方面微调实现高分辨率输出。
- 引入尺寸和裁剪的条件化方案,利用训练数据而不需要额外监督。
- 通过改进扩散模型减少伪影并提升局部细节。
- 通过提供代码和模型权重以促进可重复性和透明性。
提出的方法
- 将 UNet 容量增至 2.6B 参数,使用更多注意力块和更大的交叉注意力上下文。
- 通过将原始图像的高度和宽度进行嵌入并注入到时间步嵌入中来引入尺寸条件。
- 添加裁剪条件以通过傅里叶编码的裁剪坐标在训练中控制随机裁剪伪影。
- 通过在不同纵横比的桶上进行微调并使用专门的条件化来执行多方面训练。
- 在潜在空间中使用加噪-去噪过程(类似 SDEdit)训练一个单独的改进模型,以增强高频细节。
- 将 OpenCLIP ViT-bigG 与 CLIP ViT-L 结合用作文本编码器,并将倒数第二层输出连接起来用于条件化。
- 应用无分类器引导以将生成指向提示,而无需单独的分类器。

实验结果
研究问题
- RQ1如何对 Stable Diffusion 框架进行扩展,以提升高分辨率图像合成中的保真度和提示遵循性?
- RQ2可以为潜在扩散模型添加哪些条件化策略,以更好地利用不同大小的训练数据和纵横比?
- RQ3潜在空间中的事后改进阶段是否在不需要外部监督的情况下提升视觉质量?
- RQ4尺寸条件和裁剪条件如何影响大规模扩散模型的生成质量与伪影减少?
- RQ5多方面训练在不同输出形状上的性能有何影响?
主要发现
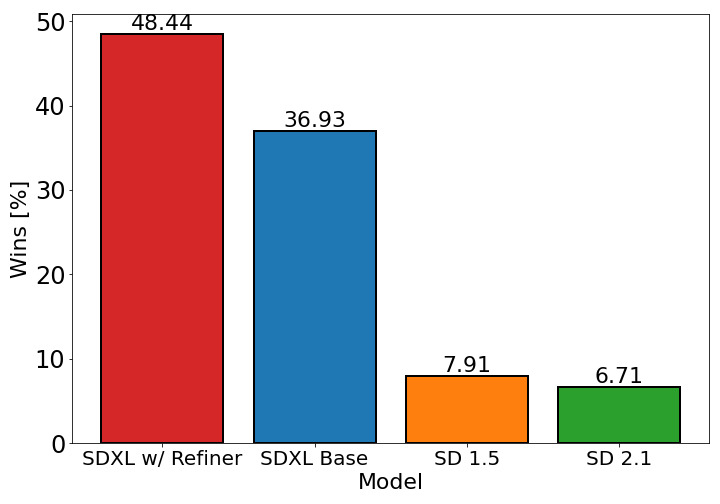
- SDXL 在用于图像质量和提示遵循性的用户研究中显著优于先前的 Stable Diffusion 版本。
- 一个改进模型在感知图像保真度方面超越基础的 SDXL,在评估中达到最高的用户偏好。
- 提供开源权重和代码以支持可重复性与透明度。
- 尺寸条件和裁剪条件减少训练时的数据损失和伪影,提升样本质量。
- 多方面训练能够在各种纵横比下实现有效的生成且不显著降解。
- 定量指标(FID/CLIP)并不能完全与人类评估一致,强调了对基础文本到图像模型进行人类评估的重要性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。