[论文解读] Searching for Best Practices in Retrieval-Augmented Generation
这篇论文系统性地研究构建检索增强生成(RAG)管道的最佳实践,评估组件选择在查询分类、分块、嵌入模型、向量数据库、检索方法、重新排序、重新打包、摘要以及生成器微调方面的影响,重点强调多模态检索和面向效率的配置。
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
研究动机与目标
- 通过广泛实验识别最佳的RAG工作流组件及其组合。
- 提供全面的评估框架和数据集,用以在一般、领域特定和多模态任务中评估RAG性能。
- 证明多模态检索能够提升对视觉输入的问答效果,并通过“检索即生成”的方法加速多模态内容生成。
提出的方法
- 通过在代表性任务上的表现对每个RAG模块进行三步法候选方法选择。
- 逐个消融以衡量各模块对整体RAG性能的贡献。
- 经验性探索各种组合,优先考虑在不同情景下的性能或效率。
- 评估使用多样化任务集(常识、事实核查、开放域问答、多跳问答、医学问答),指标包括 Faithfulness、Context Relevancy、Answer Relevancy、Answer Correctness。
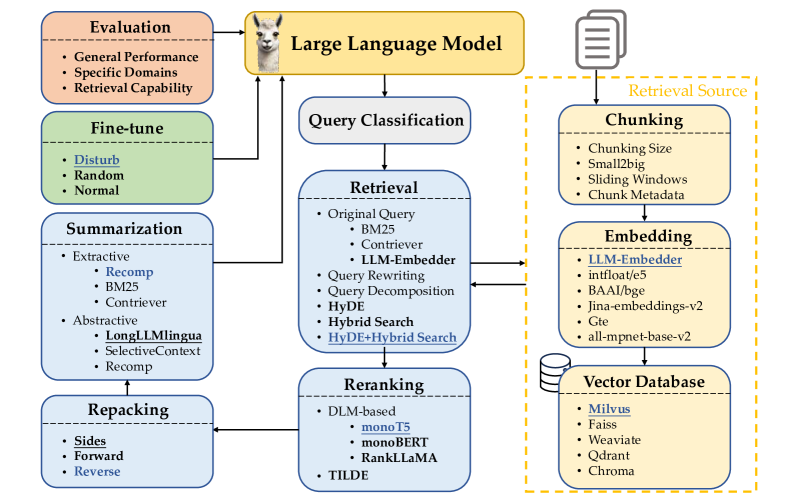
实验结果
研究问题
- RQ1对于RAG管道中的每个模块(查询分类、分块、嵌入、向量存储、检索、重新排序、重新打包、摘要以及生成器微调),哪些方法表现最佳?
- RQ2各模块如何共同作用于总体RAG性能,哪些组合在准确性与效率之间实现最佳权衡?
- RQ3多模态检索是否能够显著提升对可视输入的问答,并通过“检索即生成”策略加速多模态内容生成?
主要发现
| 方法 | TREC DL19 mAP | TREC DL19 nDCG@10 | TREC DL19 R@50 | TREC DL19 R@1k | 延迟 | DL20 mAP | DL20 nDCG@10 | DL20 R@50 | DL20 R@1k | 延迟 |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | 30.13 | 50.58 | 38.32 | 75.01 | 0.07 | 28.56 | 47.96 | 46.18 | 78.63 | 0.29 |
| Contriever | 23.99 | 44.54 | 37.54 | 74.59 | 3.06 | 23.98 | 42.13 | 43.81 | 75.39 | 0.98 |
| LLM-Embedder | 44.66 | 70.20 | 49.06 | 84.48 | 2.61 | 45.60 | 68.76 | 61.36 | 84.41 | 0.71 |
| + Query Rewriting | 44.56 | 67.89 | 51.45 | 85.35 | 7.80 | 45.16 | 65.62 | 59.63 | 83.45 | 2.06 |
| + Query Decomposition | 41.93 | 66.10 | 48.66 | 82.62 | 14.98 | 43.30 | 64.95 | 57.74 | 84.18 | 2.01 |
| + HyDE | 50.87 | 75.44 | 54.93 | 88.76 | 7.21 | 50.94 | 73.94 | 63.80 | 88.03 | 2.14 |
| + Hybrid Search | 47.14 | 72.50 | 51.13 | 89.08 | 3.20 | 47.72 | 69.80 | 64.32 | 88.04 | 0.77 |
| + HyDE + Hybrid Search | 52.13 | 73.34 | 55.38 | 90.42 | 11.16 | 53.13 | 72.72 | 66.14 | 90.67 | 2.95 |
- 将稀疏(BM25)与密集检索相结合的混合检索,结合基于 HyDE 的查询/文档转换,在合理延迟下实现了较强的性能。
- 查询改写和查询分解在所评估的设置中不如 HyDE 或混合策略有效。
- 在标准基准测试中,最佳整体RAG性能由 HyDE 加上 Hybrid Search 实现,使用 LLM-Embedder 嵌入和强重排序器(monoT5)。
- 在生成器微调阶段,使用少量相关文档加随机选取文档的混合方式,相较于仅使用相关文档或随机文档,能提高鲁棒性和有效性。
- 多模态检索显著提升对视觉输入的问答,并通过“检索即生成”方式加速多模态内容生成。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。