[论文解读] SecureFalcon: Are We There Yet in Automated Software Vulnerability Detection with LLMs?
SecureFalcon 对 FalconLLM 7b 进行微调以检测 C 代码中的漏洞,使用 FormAI 数据集,在漏洞检测中达到 94% 的准确率并提供修复建议。
Software vulnerabilities can cause numerous problems, including crashes, data loss, and security breaches. These issues greatly compromise quality and can negatively impact the market adoption of software applications and systems. Traditional bug-fixing methods, such as static analysis, often produce false positives. While bounded model checking, a form of Formal Verification (FV), can provide more accurate outcomes compared to static analyzers, it demands substantial resources and significantly hinders developer productivity. Can Machine Learning (ML) achieve accuracy comparable to FV methods and be used in popular instant code completion frameworks in near real-time? In this paper, we introduce SecureFalcon, an innovative model architecture with only 121 million parameters derived from the Falcon-40B model and explicitly tailored for classifying software vulnerabilities. To achieve the best performance, we trained our model using two datasets, namely the FormAI dataset and the FalconVulnDB. The FalconVulnDB is a combination of recent public datasets, namely the SySeVR framework, Draper VDISC, Bigvul, Diversevul, SARD Juliet, and ReVeal datasets. These datasets contain the top 25 most dangerous software weaknesses, such as CWE-119, CWE-120, CWE-476, CWE-122, CWE-190, CWE-121, CWE-78, CWE-787, CWE-20, and CWE-762. SecureFalcon achieves 94% accuracy in binary classification and up to 92% in multiclassification, with instant CPU inference times. It outperforms existing models such as BERT, RoBERTa, CodeBERT, and traditional ML algorithms, promising to push the boundaries of software vulnerability detection and instant code completion frameworks.
研究动机与目标
- 通过使用大型语言模型(LLMs)推动改进的软件漏洞检测。
- 将 FalconLLM 进行微调以对 C 代码样本进行二进制漏洞分类。
- 创建并利用 FormAI 数据集来评估漏洞检测性能。
- 通过提示一个面向修复的模型,提供漏洞修复能力。
- 评估配置变体和 SecureFalcon 的实际部署考虑。
提出的方法
- 在 FormAI 派生的 C 代码上对 FalconLLM 7b 进行微调,带有 42 个 CWE 标签。
- 通过去除头部噪声、HTML 和电子邮件地址来预处理数据;将标签数值编码。
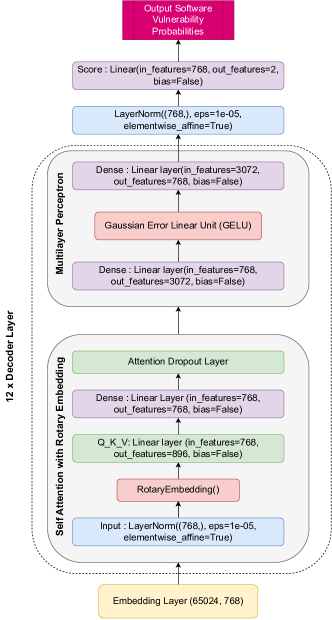
- 实现一个两标签漏洞评分头,将 768 维解码输出映射到 2 个类别,使用 sigmoid。
- 在自注意力中使用旋转位置嵌入(RoPE),在解码层中使用带 GELU 激活的 MLP。
- 使用 AdamW 优化器、学习率调度(2e-2 和 2e-5)、早停和交叉熵损失进行训练。
- 评估两种配置(121M 和 44M 参数),并在 Falcon-40B-Instruct 提示下演示漏洞修复。
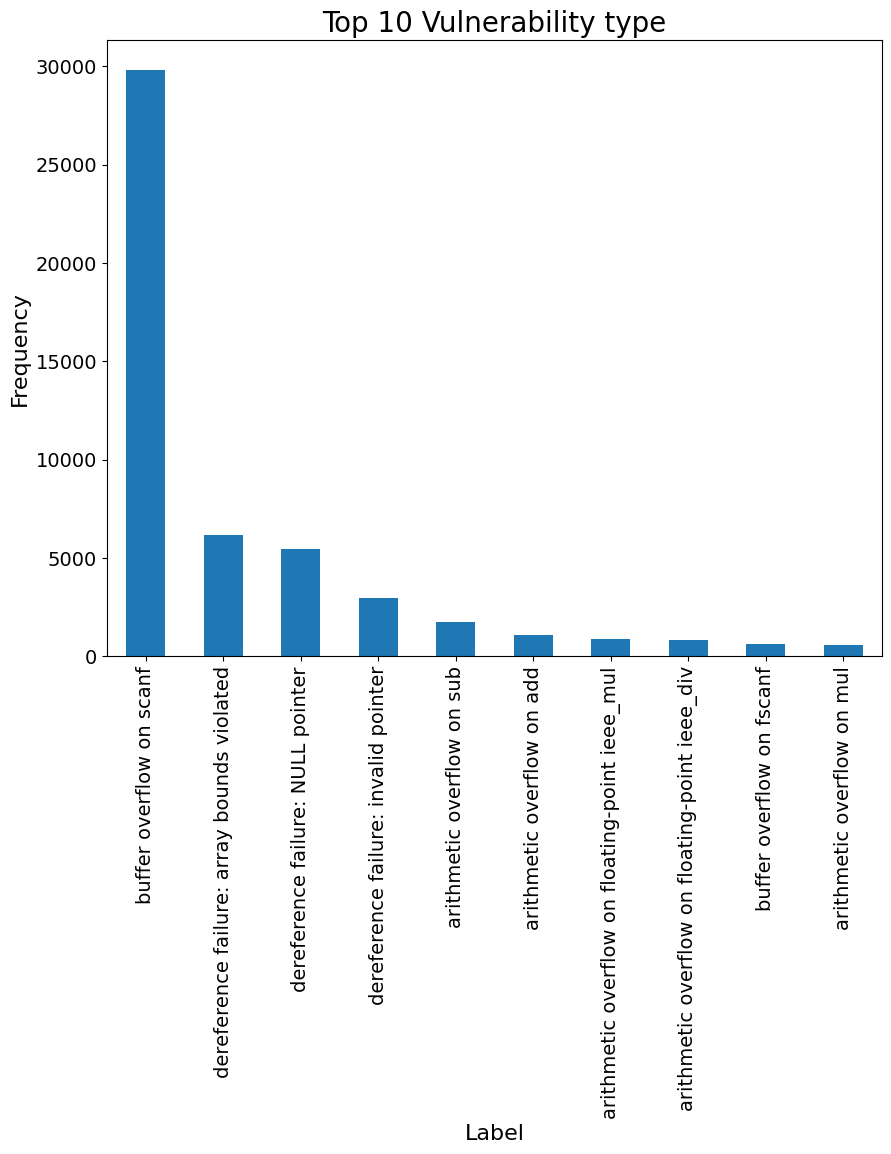
实验结果
研究问题
- RQ1FalconLLM 是否能够有效微调,以区分有漏洞的 C 代码样本与无漏洞的?
- RQ2模型规模(121M 与 44M)对漏洞检测性能有何影响?
- RQ3SecureFalcon 在基于 FormAI 的 42 个 CWE 类别中的漏洞分布上表现如何?
- RQ4系统是否可以扩展以提出检测到的漏洞的修复步骤?
主要发现
- SecureFalcon 在基于 FormAI 的数据上的漏洞检测取得高准确率(具体指标:在不同配置的训练 epoch 中报告的准确率)。
- 两种配置(121M 和 44M)在不同学习率下的训练中逐步提高准确率(LR=2e-5 和 LR=2e-2)。
- 对于 SecureFalcon 121M,LR=2e-5,训练准确率达到 0.97,验证准确率为 0.94,达到第 7 个 epoch。
- FormAI 数据集包含 112,000 个 C 程序,具有 42 个 CWE 类别,标注样本中共 197,800 个漏洞。
- 研究还展示了将 FalconLLM 作为修复系统,在漏洞检测后提出修复建议。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。