[论文解读] (Security) Assertions by Large Language Models
本文评估一个开箱即用的大语言模型,用于自动生成硬件安全断言,使用基准测试套件和基于提示的提示,并发布一个用于评估的开源框架。
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.
研究动机与目标
- 在断言捕捉设计意图和漏洞检查的情况下,推动硬件安全验证。
- 评估开箱即用的LLM是否能从自然语言提示生成SystemVerilog安全断言。
- 开发一个包含基准测试、提示和验证流水线的评估框架,以衡量LLM的性能。
- 开源该框架和基准测试,以支持在LLM辅助的硬件断言生成方面的进一步研究。
提出的方法
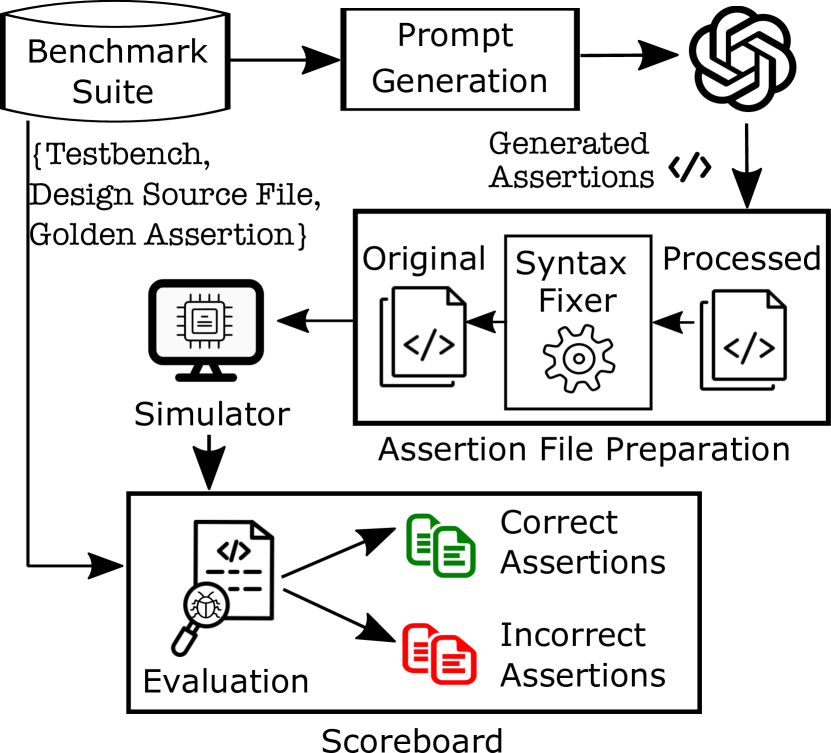
- 设计一个真实世界硬件设计的基准测试套件,包含相应的黄金参考断言。
- 创建一个提示生成器,将设计上下文、示例断言以及注释中的不同细节等级结合起来。
- 实现一个断言文件生成器,修复常见的LLM错误并为验证准备处理后的断言。
- 使用仿真器(Modelsim)根据触发违规的匹配,将LLM生成的断言与黄金参考进行比较。
- 使用记分板对处理后的断言进行正确性评分,通过匹配触发违规的输入将其分类为正确或不正确。
实验结果
研究问题
- RQ1RQ1: 开箱即用的大语言模型能否生成硬件安全断言?
- RQ2RQ2: 不同类型的提示如何影响生成断言的质量和正确性?
主要发现
- 一个以LLM驱动的流程可以在一系列基准测试中生成硬件安全断言。
- 提示设计(设计上下文、注释细节、示例和开头)显著影响断言质量。
- 一组固定的自动修复可以修复常见的语法/拼写错误,而不会降低性能。
- 处理和去重产生大量可用断言,部分断言在验证中与黄金参考匹配。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。