[论文解读] Segment Anything Model for Medical Image Analysis: an Experimental Study
该论文在19个跨模态的医学影像数据集上评估 Segment Anything Model (SAM) 的零-shot 分割性能和交互模式,比较与其他交互方法并详细阐述提示策略。
Training segmentation models for medical images continues to be challenging due to the limited availability of data annotations. Segment Anything Model (SAM) is a foundation model that is intended to segment user-defined objects of interest in an interactive manner. While the performance on natural images is impressive, medical image domains pose their own set of challenges. Here, we perform an extensive evaluation of SAM's ability to segment medical images on a collection of 19 medical imaging datasets from various modalities and anatomies. We report the following findings: (1) SAM's performance based on single prompts highly varies depending on the dataset and the task, from IoU=0.1135 for spine MRI to IoU=0.8650 for hip X-ray. (2) Segmentation performance appears to be better for well-circumscribed objects with prompts with less ambiguity and poorer in various other scenarios such as the segmentation of brain tumors. (3) SAM performs notably better with box prompts than with point prompts. (4) SAM outperforms similar methods RITM, SimpleClick, and FocalClick in almost all single-point prompt settings. (5) When multiple-point prompts are provided iteratively, SAM's performance generally improves only slightly while other methods' performance improves to the level that surpasses SAM's point-based performance. We also provide several illustrations for SAM's performance on all tested datasets, iterative segmentation, and SAM's behavior given prompt ambiguity. We conclude that SAM shows impressive zero-shot segmentation performance for certain medical imaging datasets, but moderate to poor performance for others. SAM has the potential to make a significant impact in automated medical image segmentation in medical imaging, but appropriate care needs to be applied when using it.
研究动机与目标
- 评估 SAM 在广泛的医学影像数据集上的零-shot 分割性能。
- 描述提示策略(点提示 vs 框提示)及提示迭代如何影响 SAM 的性能。
- 在各类任务中将 SAM 与其他交互式分割方法(RITM、SimpleClick、FocalClick)进行比较。
- 识别提示歧义效应并为医学影像应用提出实用的使用模式。
提出的方法
- 在19个公开可用的医学影像数据集上评估 SAM,覆盖 MRI、CT、X-ray、超声和 PET。
- 定义五种非迭代提示模式(点提示或框提示)以及一个迭代提示方案以模拟用户交互。
- 以 IoU 作为主要准确性指标,以 oracle 性能作为上限代理。
- 在非迭代提示和迭代提示下,将 SAM 与 RITM、SimpleClick、FocalClick 进行比较。
- 分析 segment-everything 模式和对象大小对性能的影响。
- 提供定性可视化并讨论提示歧义效应。
实验结果
研究问题
- RQ1在多样的模态和解剖结构上,SAM 在医学影像的零-shot 分割中表现如何?
- RQ2哪些提示策略(点提示 vs 框提示)和模式在处理含多部分结构的医学对象时能获得最佳的 SAM 性能?
- RQ3在单个和多个提示下,SAM 如何与其他交互式分割方法进行比较?
- RQ4迭代提示是否显著提升 SAM 的性能,尤其是对于具有多部分或提示歧义的对象?
- RQ5将 SAM 融入医学影像标注和模型训练时,会出现哪些实用的使用模式?
主要发现
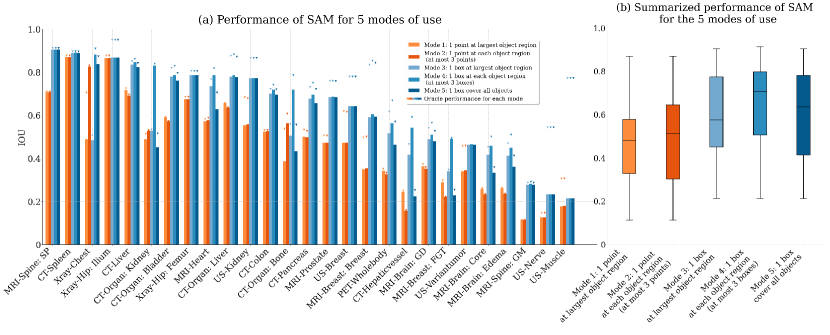
- 在28个任务中的 SAM 性能差异很大,从 IoU 0.1135(脊椎 MRI)到 0.8650(髋部 X-ray)。
- 框提示优于点提示,其中 Mode 4(每个对象部分一个框)在所有任务上实现了最佳平均 IoU 0.6542。
- 在单点提示设置下,SAM 通常优于 RITM、SimpleClick 和 FocalClick;在 oracle 模式下,SAM 在 26/28 个任务中领先。
- 迭代提示对 SAM 的提升有限,而 SimpleClick 与 RITM 在增加额外点时提升更大,在某些情况下甚至超过 SAM。
- SAM 对某些数据集显示零-shot 潜力,但对其他数据集表现中等到较差,表明需要谨慎使用与提示策略。
- 提示歧义可能产生多种输出;SAM 的高置信度映射往往类似区域增长的分割区域;低置信度输出变化更大。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。