[论文解读] Self-Ensembling with GAN-based Data Augmentation for Domain Adaptation in Semantic Segmentation
本文提出了一种用于语义分割的新型领域自适应框架,结合了基于生成对抗网络(GAN)的、目标引导的、无循环的数据增强(TGCF-DA)与自集成方法,以减少领域偏移。通过从目标域生成语义一致且风格迁移的图像,并利用教师网络生成的伪标签,该方法在GTA5→Cityscapes和SYNTHIA→Cityscapes基准上实现了最先进(SOTA)的性能表现,优于现有方法。
Deep learning-based semantic segmentation methods have an intrinsic limitation that training a model requires a large amount of data with pixel-level annotations. To address this challenging issue, many researchers give attention to unsupervised domain adaptation for semantic segmentation. Unsupervised domain adaptation seeks to adapt the model trained on the source domain to the target domain. In this paper, we introduce a self-ensembling technique, one of the successful methods for domain adaptation in classification. However, applying self-ensembling to semantic segmentation is very difficult because heavily-tuned manual data augmentation used in self-ensembling is not useful to reduce the large domain gap in the semantic segmentation. To overcome this limitation, we propose a novel framework consisting of two components, which are complementary to each other. First, we present a data augmentation method based on Generative Adversarial Networks (GANs), which is computationally efficient and effective to facilitate domain alignment. Given those augmented images, we apply self-ensembling to enhance the performance of the segmentation network on the target domain. The proposed method outperforms state-of-the-art semantic segmentation methods on unsupervised domain adaptation benchmarks.
研究动机与目标
- 解决从合成(源)域到真实世界(目标)域进行语义分割时的领域偏移挑战。
- 克服自集成方法中人工数据增强在分割任务中导致的空间错位问题。
- 开发一种高效、无循环的基于GAN的数据增强方法,可在保留语义一致性的同时实现目标域风格迁移。
- 将自集成与所提出的增强方法结合,以提升模型在目标域上的泛化能力。
- 在标准无监督领域自适应语义分割基准上实现最先进性能。
提出的方法
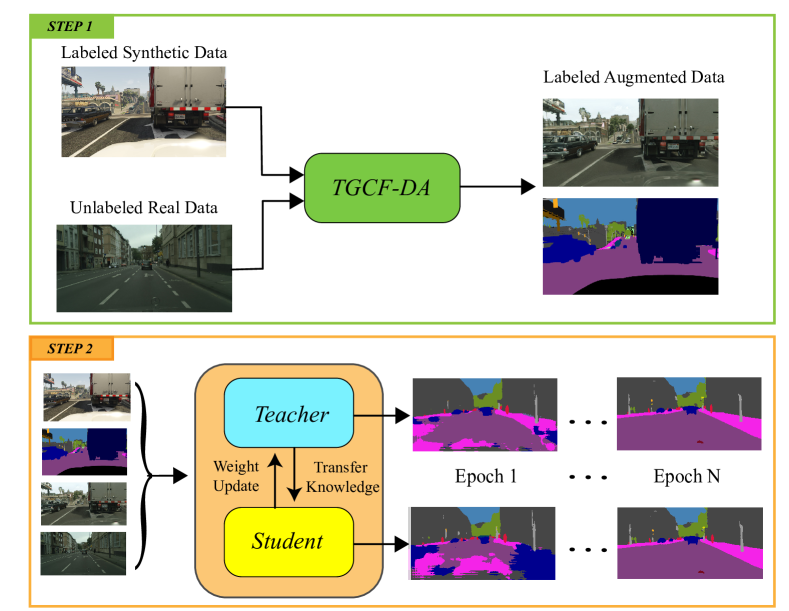
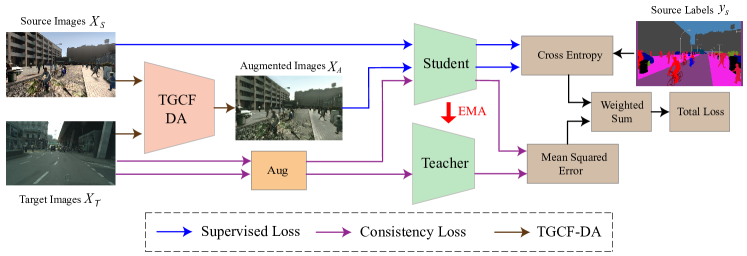
- 提出目标引导且无循环的数据增强(TGCF-DA),一种基于GAN的方法,通过从目标域图像中迁移风格来生成增强图像,同时保持语义内容。
- 使用语义一致性损失约束生成器,确保增强图像在全局和局部结构上的保持。
- 以目标域风格特征作为条件,生成逼真且领域对齐的增强图像,而无需依赖循环一致性。
- 采用教师-学生架构的自集成框架,其中教师网络的预测结果作为学生网络的伪标签。
- 应用具有自适应加权的渐进式一致性损失,逐步增加训练过程中一致性损失的影响。
- 使用指数移动平均(EMA)结合退火衰减策略,以稳定教师网络随时间的预测结果。
实验结果
研究问题
- RQ1基于GAN的目标引导数据增强是否能在不依赖循环一致性的前提下减少语义分割中的领域偏移?
- RQ2与标准数据增强相比,使用GAN增强数据的自集成方法在领域自适应性能上是否有所提升?
- RQ3所提出的无循环、语义一致的增强方法是否能缓解自集成方法在分割任务中导致的空间错位问题?
- RQ4EMA衰减系数和一致性损失渐进系数等超参数如何影响模型收敛与性能表现?
- RQ5与基线自集成方法相比,该方法在提升各类IoU,尤其是少数类(如'bus')方面,改善程度如何?
主要发现
- 所提方法在GTA5→Cityscapes和SYNTHIA→Cityscapes基准上实现了最先进性能,优于现有SOTA方法。
- 在GTA5→Cityscapes上,该方法实现了42.5的平均IoU,显著优于基线TGCF-DA方法(41.3),当引入自集成后性能进一步提升。
- 在SYNTHIA→Cityscapes上,该方法达到38.5的平均IoU,表明在两个基准上均表现出一致的性能增益。
- 各类别IoU分析显示,对多数类(如'road')的提升更大,而对少数类(如'bus')的提升较小,表明类别不平衡对伪标签质量有显著影响。
- 超参数消融实验表明,后期训练中EMA衰减系数为0.999,且渐进系数δ₀ = 30时,性能达到最优。
- 可视化结果证实,适当的语义约束(λ_sem = 10)可有效保持图像结构,而约束不足(λ_sem = 1)则导致物体混合与语义退化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。