[论文解读] Self-Refine: Iterative Refinement with Self-Feedback
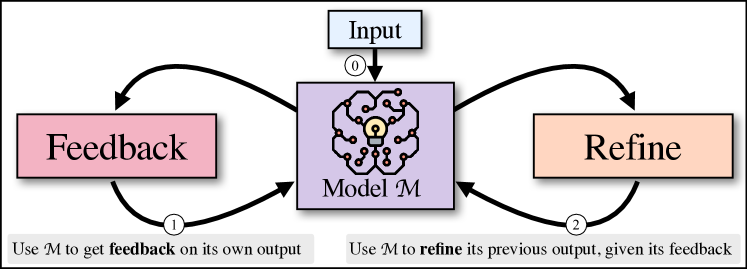
Self-Refine 使用单一大型语言模型生成初始输出,然后提供反馈并迭代改进,在无额外训练的情况下实现跨任务的提升。
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce Self-Refine, an approach for improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an initial output using an LLMs; then, the same LLMs provides feedback for its output and uses it to refine itself, iteratively. Self-Refine does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as the generator, refiner, and feedback provider. We evaluate Self-Refine across 7 diverse tasks, ranging from dialog response generation to mathematical reasoning, using state-of-the-art (GPT-3.5, ChatGPT, and GPT-4) LLMs. Across all evaluated tasks, outputs generated with Self-Refine are preferred by humans and automatic metrics over those generated with the same LLM using conventional one-step generation, improving by ~20% absolute on average in task performance. Our work demonstrates that even state-of-the-art LLMs like GPT-4 can be further improved at test time using our simple, standalone approach.
研究动机与目标
- 通过人类写作和解决问题的启发,推动通过迭代自反馈改进LLM输出。
- 提出一种无需训练的方法,使用同一LLM进行生成、反馈和 refinement。
- 在多样任务上证明有效性,并分析反馈质量和迭代深度的影响。
提出的方法
- 用基线LLM生成初始输出。
- 对同一LLM进行提示,产出可执行的对其输出的反馈。
- 通过对同一LLM的精炼提示,使用反馈对输出进行改进。
- 在达到任务特定停止条件之前迭代反馈和改进(最多4次迭代)。
- 使用少样本提示来引导生成、反馈和改进,而无需外部训练。
实验结果
研究问题
- RQ1单个LLM在不进行额外训练的情况下,是否能够通过迭代自反馈和改进来提升自身输出?
- RQ2自生成反馈的质量如何影响改进结果?
- RQ3多次反馈-改进迭代对不同任务的影响是什么?
- RQ4自我 refinement 是否在跨领域任务中优于单次生成?
主要发现
| Task | GPT-3.5 Base | GPT-3.5 + Ours | ChatGPT Base | ChatGPT + Ours | GPT-4 Base | GPT-4 + Ours |
|---|---|---|---|---|---|---|
| 情感反转 | 8.8 | 30.4 (↑ 21.6) | 11.4 | 43.2 (↑ 31.8) | 3.8 | 36.2 (↑ 32.4) |
| 对话回应 | 36.4 | 63.6 (↑ 27.2) | 40.1 | 59.9 (↑ 19.8) | 25.4 | 74.6 (↑ 49.2) |
| 代码优化 | 14.8 | 23.0 (↑ 8.2) | 23.9 | 27.5 (↑ 3.6) | 27.3 | 36.0 (↑ 8.7) |
| 代码可读性 | 37.4 | 51.3 (↑ 13.9) | 27.7 | 63.1 (↑ 35.4) | 27.4 | 56.2 (↑ 28.8) |
| 数学推理 | 64.1 | 64.1 (0) | 74.8 | 75.0 (↑ 0.2) | 92.9 | 93.1 (↑ 0.2) |
| 首字母缩略词生成 | 41.6 | 56.4 (↑ 14.8) | 27.2 | 37.2 (↑ 10.0) | 30.4 | 56.0 (↑ 25.6) |
| 受限生成 | 28.0 | 37.0 (↑ 9.0) | 44.0 | 67.0 (↑ 23.0) | 15.0 | 45.0 (↑ 30.0) |
- 在7个任务中,自我 refinement 相较于单次生成,获得更高的人类和自动偏好。
- GPT-4 结合自我 refinement 显示出显著的绝对提升(例如 Code Optimization 从 27.3% 提升到 36.0%;+8.7)。
- 在基于偏好的任务中,提升尤为显著(例如对话回应:GPT-4 从 25.4 提升到 74.6)。
- 受限生成在通过迭代反馈后探索更多输出时受益显著。
- 代码相关任务也有所提升,使用 Codex 时可达到多达 13% 的绝对提升。
- 可操作、具体的反馈对性能至关重要;通用或无反馈会降低结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。