[论文解读] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SelfCheckGPT 是一种零资源、黑箱式幻觉检测方法,针对生成型大语言模型,使用多次随机采样来评估信息一致性并在没有外部数据库的情况下标记非事实内容。
Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods.
研究动机与目标
- 动机与解决在没有外部知识库的情况下,黑箱式大语言模型中的事实性幻觉挑战。
- 提出一个基于采样的框架(SelfCheckGPT)来衡量多个 LLM 采样之间的一致性。
- 在一个基于 WikiBio 的 GPT-3 数据集上,带有句子级和段落级事实性标签,评估该方法相对于灰箱和黑箱基线的表现。
提出的方法
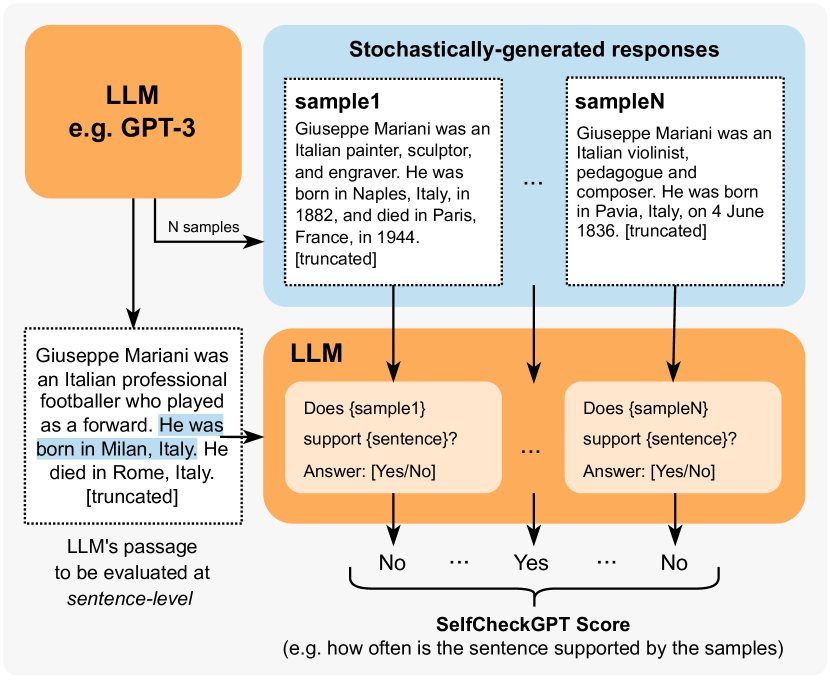
- 对给定提示从同一 LLM 中抽取 N 个随机样本。
- 使用变体计算句子级事实性分数:BERTScore、基于问答的一致性、 unigram 最大 n-gram、NLI,以及基于提示的提示方法。
- 对于 n-gram,在样本和主响应上训练一个简单的 n-gram 模型以估计标记概率。
- 使用 NLI(在 MNLI 上微调的 DeBERTa-v3-large)来计算句子评估的矛盾概率。
- 使用基于提示的评估器(SelfCheckGPT-Prompt)向 LLM 查询一个句子是否得到采样上下文的支持。
- 报告句子级分数并通过平均汇总得到段落级分数。
实验结果
研究问题
- RQ1在没有外部数据库的情况下,零资源、黑箱采样是否能检测事实性句子与非事实性句子?
- RQ2哪些 SelfCheckGPT 变体在句子级和段落级与人类对事实性的判断的相关性最好?
- RQ3SelfCheckGPT 与灰箱及其他黑箱方法在检测性能和与人类评估相关性方面的比较如何?
主要发现
| Method | NonFact | NonFact* | Factual | Pearson | Spearman |
|---|---|---|---|---|---|
| Random | 72.96 | 29.72 | 27.04 | - | - |
| GPT-3 probabilities (LLM, grey-box) Avg(-log p) | 83.21 | 38.89 | 53.97 | 57.04 | 53.93 |
| GPT-3 probabilities (LLM, grey-box) Avg(H) | 80.73 | 37.09 | 52.07 | 55.52 | 50.87 |
| GPT-3 probabilities (LLM, grey-box) Max(-log p) | 87.51 | 35.88 | 50.46 | 57.83 | 55.69 |
| GPT-3 probabilities (LLM, grey-box) Max(H) | 85.75 | 32.43 | 50.27 | 52.48 | 49.55 |
| LLaMA-30B (Proxy LLM, black-box) Avg(-log p) | 75.43 | 30.32 | 41.29 | 21.72 | 20.20 |
| LLaMA-30B (Proxy LLM, black-box) Avg(H) | 80.80 | 39.01 | 42.97 | 33.80 | 39.49 |
| LLaMA-30B (Proxy LLM, black-box) Max(-log p) | 74.01 | 27.14 | 31.08 | -22.83 | -22.71 |
| LLaMA-30B (Proxy LLM, black-box) Max(H) | 80.92 | 37.32 | 37.90 | 35.57 | 38.94 |
| SelfCheckGPT w/ BERTScore | 81.96 | 45.96 | 44.23 | 58.18 | 55.90 |
| SelfCheckGPT w/ QA | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
| SelfCheckGPT w/ Unigram (max) | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| SelfCheckGPT w/ NLI | 92.50 | 45.17 | 66.08 | 74.14 | 73.78 |
| SelfCheckGPT w/ Prompt | 93.42 | 53.19 | 67.09 | 78.32 | 78.30 |
- SelfCheckGPT 变体在非事实和事实句子上的句子级 AUC-PR 超过若干基线。
- 基于 NLI 的 SelfCheckGPT 在句子级检测方面取得较强的性能,接近基于提示的评估。
- 基于提示的 SelfCheckGPT 在段落级与人类判断的相关性方面表现最佳(Pearson 78.32,Spearman 78.30)。
- 基于 NLI 的 SelfCheckGPT 在性能与计算成本之间提供了一个现实的权衡。
- Unigram 最大 n-gram SelfCheckGPT 在相对较低的计算成本下提供有竞争力的句子级结果。
- 与代理 LLM(如 LLaMA)相比,自采样方法在与人类判断的相关性方面表现更优。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。