[论文解读] Semantic Segmentation using Vision Transformers: A survey
本综述回顾用于语义分割的 Vision Transformer (ViT) 架构,比较 SETR、Swin Transformer、Segmenter、SegFormer、PVT 等模型在 ADE20K、Cityscapes 等基准数据集上的表现,并讨论数据策略与损失函数。
Semantic segmentation has a broad range of applications in a variety of domains including land coverage analysis, autonomous driving, and medical image analysis. Convolutional neural networks (CNN) and Vision Transformers (ViTs) provide the architecture models for semantic segmentation. Even though ViTs have proven success in image classification, they cannot be directly applied to dense prediction tasks such as image segmentation and object detection since ViT is not a general purpose backbone due to its patch partitioning scheme. In this survey, we discuss some of the different ViT architectures that can be used for semantic segmentation and how their evolution managed the above-stated challenge. The rise of ViT and its performance with a high success rate motivated the community to slowly replace the traditional convolutional neural networks in various computer vision tasks. This survey aims to review and compare the performances of ViT architectures designed for semantic segmentation using benchmarking datasets. This will be worthwhile for the community to yield knowledge regarding the implementations carried out in semantic segmentation and to discover more efficient methodologies using ViTs.
研究动机与目标
- 评估基于 ViT 的架构如何应对语义分割中密集预测的挑战。
- 比较架构类型(纯 ViT 与混合型)及其用于分割的解码头在准确性与效率上的表现。
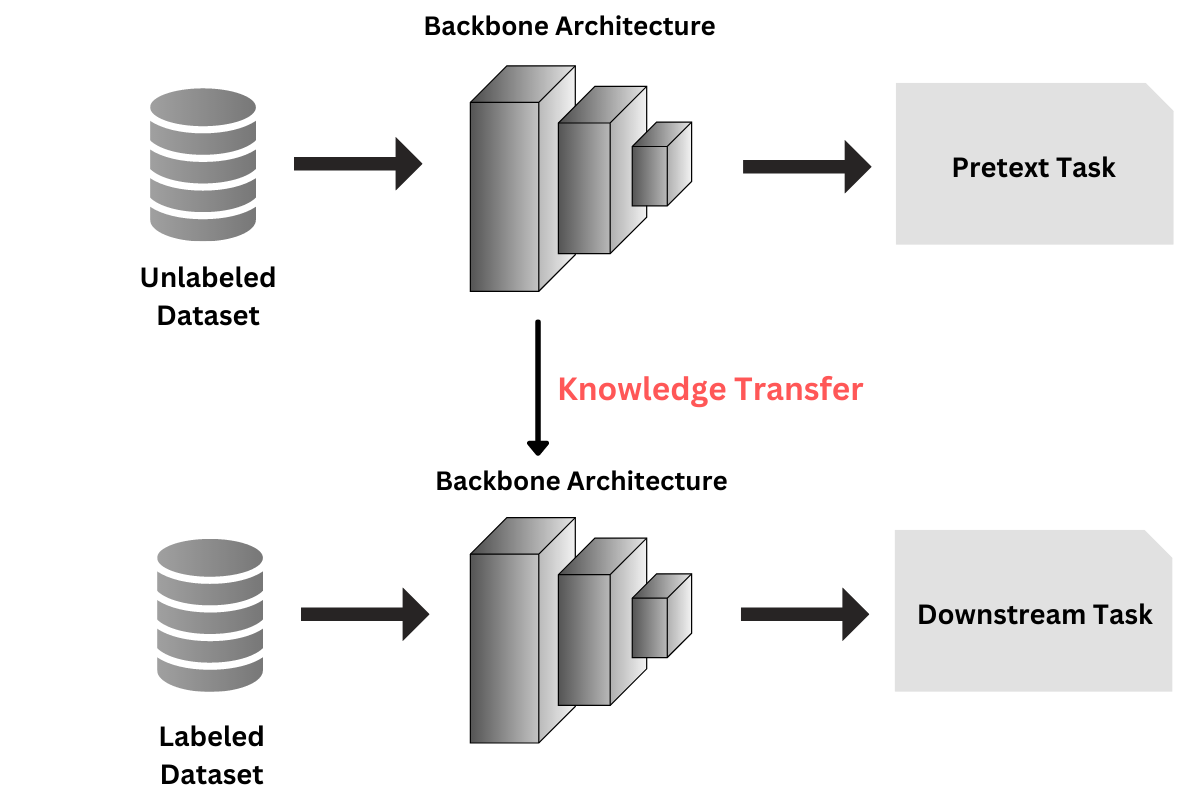
- 识别能够在标注数据有限的情况下使 ViT 成功的与数据相关的策略(迁移学习、自监督学习)。
- 总结常用的损失函数与基准数据集,为未来的 ViT 分割研究提供指南。
提出的方法
- 给出基于 ViT 的分割架构的分类法(如 SETR、Swin Transformer、Segmenter、SegFormer、PVT)。
- 讨论诸如层级骨干网络、补丁合并和高效自注意力等架构改进,以降低计算量。
- 强调基准结果与数据集使用情况(ADE20K、Cityscapes、PASCAL-Context 等)。
- 描述在分割任务中针对 ViTs 的实际数据策略,包括自监督学习与迁移学习。
- 回顾损失函数(交叉熵、加权交叉熵、焦点损失、Dice/IoU 损失)及其对分割准确性的影响。
![Figure 1: Architecture of the Vision Transformer. The model splits an image into a number of fixed-size patches and linearly embeds them with position embeddings (left). Then the result is fed into a standard transformer encoder (right). Adapted from [ 2 ] .](https://ar5iv.labs.arxiv.org/html/2305.03273/assets/vit_figure.png)
实验结果
研究问题
- RQ1已提出哪些基于 ViT 的语义分割架构,它们在标准数据集上的表现如何?
- RQ2设计选择(骨干类型、解码器设计、补丁大小)如何影响分割准确性与效率?
- RQ3哪些数据策略(监督学习、自监督学习、迁移学习)最能缓解 ViT 在分割任务中的数据需求高的问题?
- RQ4在不同数据集上,哪些损失函数最适用于 ViT 的逐像素分割?
主要发现
- Swin Transformer 通过分层的、线性复杂度的注意力机制实现了较强的结果;在所引工作的 ADE20K 验证集上报告了 53.5% 的 mIoU。
- Segmenter 采用 ViT 骨干和掩码变换器解码器,利用全局上下文在分割方面优于基于 CNN 的方法。
- SegFormer 采用分层编码器、轻量级 MLP 解码器和无位置编码设计,提供具有竞争力的结果和鲁棒性,变体从 B0 到 B5。
- SETR 引入用于分割的纯 Transformer 编码器,像 SETR-PUP 和 SETR-MLA 这样的变体在 ADE20K 和 Pascal Context 上展示了性能。
- PVT 提供渐进式金字塔骨干,以平衡分辨率和计算量,提升密集预测任务的效率。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。