[论文解读] Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
本文提出语义熵,一种无监督的自然语言生成不确定性度量,通过聚类含义来考虑语义等价性,并在含义上估计不确定性,而非对标记序列,从而提高对问答任务中模型准确性的预测性。
We introduce a method to measure uncertainty in large language models. For tasks like question answering, it is essential to know when we can trust the natural language outputs of foundation models. We show that measuring uncertainty in natural language is challenging because of "semantic equivalence" -- different sentences can mean the same thing. To overcome these challenges we introduce semantic entropy -- an entropy which incorporates linguistic invariances created by shared meanings. Our method is unsupervised, uses only a single model, and requires no modifications to off-the-shelf language models. In comprehensive ablation studies we show that the semantic entropy is more predictive of model accuracy on question answering data sets than comparable baselines.
研究动机与目标
- 在自由形式的NLG中,语义含义而非表面形式重要,因此有必要建立可靠的不确定性度量。
- 提出将语义熵定义为对含义的熵,而非对标记的熵。
- 开发一种实用的、无监督的方法,使用单个模型且不对现成语言模型进行修改。
- 通过广泛的消融实验,在开放式和闭卷问答数据集(TriviaQA 和 CoQA)上证明其有效性。
提出的方法
- 通过双向蕴含来定义语义等价,以聚类意义相同的输出。
- 从单个模型中采样多条序列并将它们聚类成基于含义的等价类。
- 通过在每个含义类中聚合标记级概率来计算含义分布的熵,从而得到语义熵。
- 使用蒙特卡罗估计来近似语义熵,因为并非所有含义都能被观测到。
- 分析采样策略,包括温度和方法(多项式采样/束搜索采样),并讨论长度归一化。
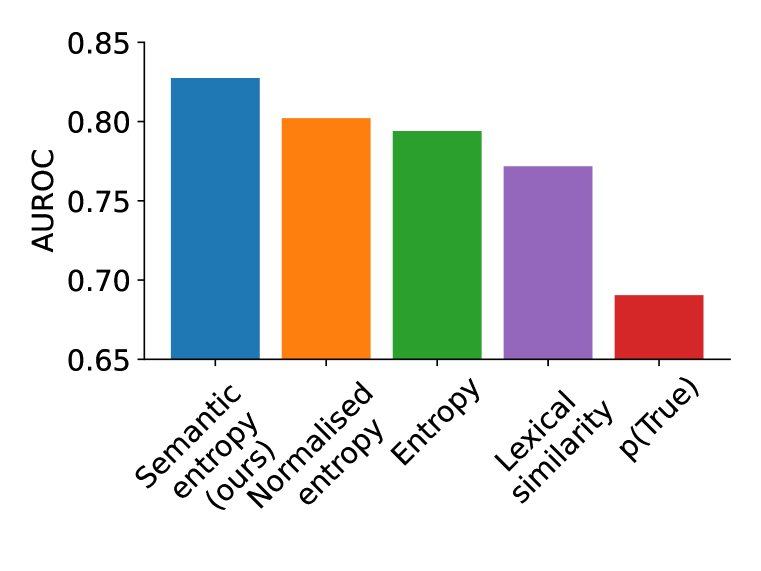
实验结果
研究问题
- RQ1NLG的不确定性是否可以以含义为中心,而非以标记为中心?我们是否可以在无需监督的情况下对其进行量化?
- RQ2语义熵是否比标准熵或基线更能预测在问答任务中的模型准确性?
- RQ3应如何配置采样和聚类以在基于含义的不确定性估计中实现多样性和准确性的平衡?
- RQ4该方法是否在不同规模的模型以及像TriviaQA和CoQA这样的问答数据集上具有鲁棒性?
主要发现
- 语义熵在预测开放式和闭卷问答任务中的模型正确性方面优于基线。
- 该方法随着模型规模增加而具备可扩展性,更多样本带来收益,同时不需要修改模型或集成。
- 一种双向蕴含聚类算法能够有效地将语义等价的输出聚集到一起,以实现基于含义的不确定性。
- 在中等采样温度下能够实现最佳的不确定性性能,平衡多样性与准确性。
- 较长的句子会影响联合似然,在某些情景下催生对长度归一化熵的讨论。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。