[论文解读] Sentiment Analysis through LLM Negotiations
本文提出一种多-LLM协商框架,其中具备推理能力的生成器和推理派生的判别器迭代协商情感决策,在多个基准上比单一LLM的ICL基线实现更高的准确性。
A standard paradigm for sentiment analysis is to rely on a singular LLM and makes the decision in a single round under the framework of in-context learning. This framework suffers the key disadvantage that the single-turn output generated by a single LLM might not deliver the perfect decision, just as humans sometimes need multiple attempts to get things right. This is especially true for the task of sentiment analysis where deep reasoning is required to address the complex linguistic phenomenon (e.g., clause composition, irony, etc) in the input. To address this issue, this paper introduces a multi-LLM negotiation framework for sentiment analysis. The framework consists of a reasoning-infused generator to provide decision along with rationale, a explanation-deriving discriminator to evaluate the credibility of the generator. The generator and the discriminator iterate until a consensus is reached. The proposed framework naturally addressed the aforementioned challenge, as we are able to take the complementary abilities of two LLMs, have them use rationale to persuade each other for correction. Experiments on a wide range of sentiment analysis benchmarks (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) demonstrate the effectiveness of proposed approach: it consistently yields better performances than the ICL baseline across all benchmarks, and even superior performances to supervised baselines on the Twitter and movie review datasets.
研究动机与目标
- 通过上下文学习进行情感分析时,单一LLM在处理复杂语言现象(如讽刺、否定)方面的局限性。
- 提出一个生成-判别式的多-LLM协商框架,以提高情感分类的准确性和鲁棒性。
- 证明两個LLM之间的协作,及可选的第三者参与,在多样数据集上能取得比有监督基线更好的结果。
- 展示角色翻转的协商和基于推理的解释如何提高决策质量和可解释性。
提出的方法
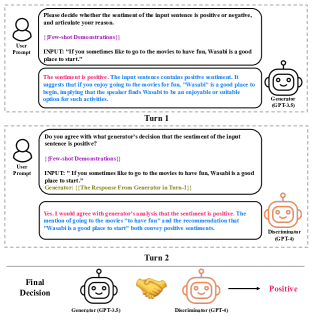
- 我们引入一个包含推理注入的生成器(G)和一个推理派生解释的判别器(D)的两-LLM设置。
- G 产出一个情感决策以及一个基于检索到的演示样本的结构化推理链。
- D 评估 G 的输出,提供理由,并在达成共识前可触发迭代协商。
- 角色翻转的协商在 G 和 D 之间交换角色,以进一步提炼决策。
- 若仍存在分歧,将调用第三个 LLM 来汇总并对六个协商结果进行投票。
- 实验以 GPT-3.5、GPT-4、和 InstructGPT-3.5 为骨干;RoBERTa-Large 用于基于 KNN 的演示检索。
实验结果
研究问题
- RQ1两个 LLM 之间的生成-判别协商是否能在情感分析中超越单一 LLM 的上下文学习?
- RQ2角色翻转(以及可选的第三-LLM 投票)是否在多样的情感基准上进一步提高准确性和鲁棒性?
- RQ3在协商过程中包含显式推理链对性能的影响是什么?
- RQ4所提方法与标准数据集(如 SST-2、MR、Twitter、Yelp、Amazon、IMDB)上的有监督基线相比如何?
主要发现
- 两-LLM 协商框架在多个数据集上持续较 vanilla ICL 基线提升准确性。
- 与两个不同的 LLM 的协商在 MR、Twitter 和 IMDB 上明显优于自我协商(一-LLM)设置。
- 角色翻转的协商以及增加第三个 LLM 进一步提升性能,使得决策能以共识为导向。
- 该方法在 Twitter 和 Movie Review 数据集上可超越某些有监督基线,并在若干基准上缩小与 RoBERTa-Large 的差距。
- 包含推理的提示至关重要;在协商设置中移除推理步骤对性能的影响大于在单一 LLM 基线中的影响。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。