[论文解读] Sequential Attend, Infer, Repeat: Generative Modelling of Moving Objects
sqair extends AIR to video by incorporating a spatio-temporal state-space model, enabling unsupervised discovery, tracking, and generation of moving objects across frames with improved handling of occlusion and overlap.
We present Sequential Attend, Infer, Repeat (SQAIR), an interpretable deep generative model for videos of moving objects. It can reliably discover and track objects throughout the sequence of frames, and can also generate future frames conditioning on the current frame, thereby simulating expected motion of objects. This is achieved by explicitly encoding object presence, locations and appearances in the latent variables of the model. SQAIR retains all strengths of its predecessor, Attend, Infer, Repeat (AIR, Eslami et. al., 2016), including learning in an unsupervised manner, and addresses its shortcomings. We use a moving multi-MNIST dataset to show limitations of AIR in detecting overlapping or partially occluded objects, and show how SQAIR overcomes them by leveraging temporal consistency of objects. Finally, we also apply SQAIR to real-world pedestrian CCTV data, where it learns to reliably detect, track and generate walking pedestrians with no supervision.
研究动机与目标
- 在无监督的前提下,推动学习可解释且随时间保持一致的对象表示。
- 将 AIR 框架扩展到序列,以建模跨帧的对象持久性、外观和运动。
- 开发一种发现-传播推断机制,以跟踪和管理对象的进入、持续存在或从场景中消失。
- 在合成数据和真实世界数据上展示改进的对象计数、重建能力以及对下游任务的实用性。
提出的方法
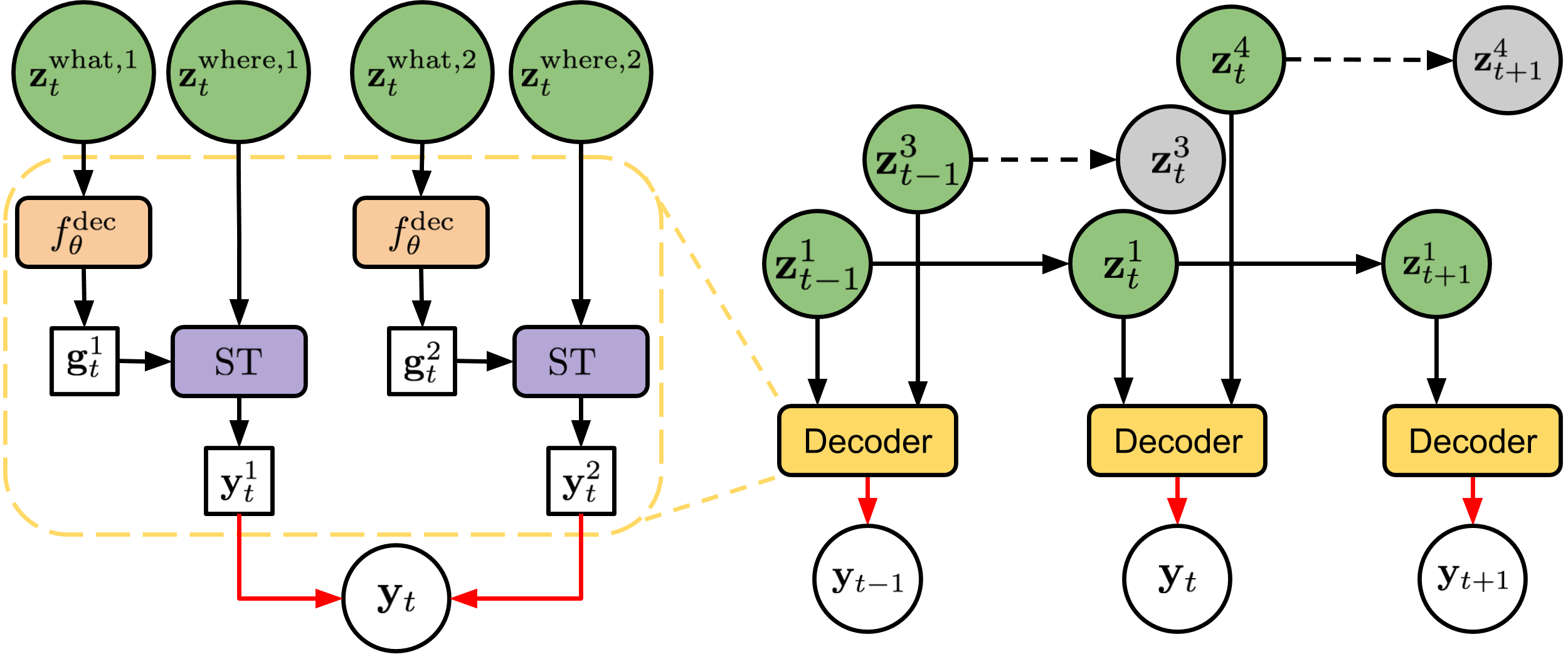
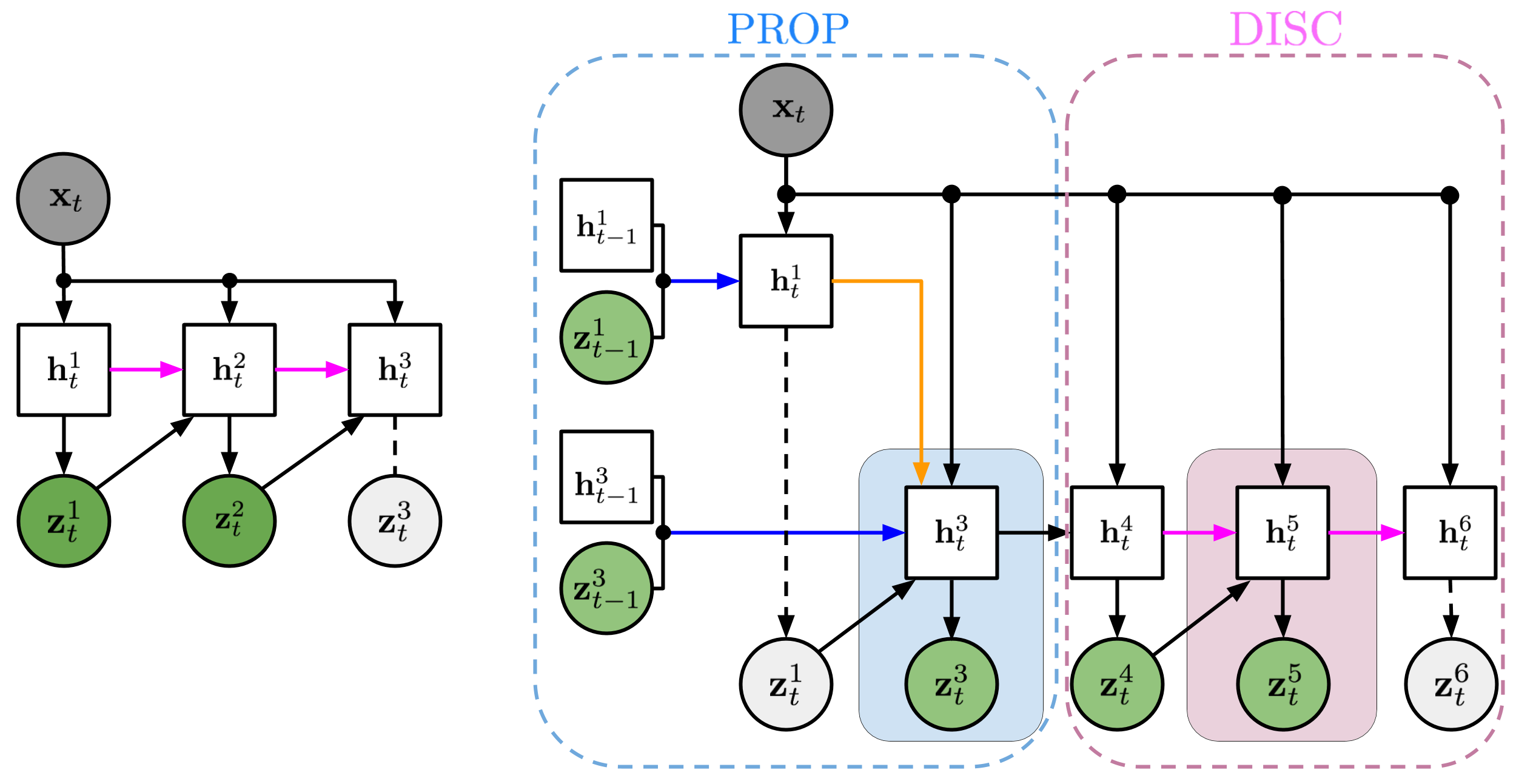
- 将 AIR 扩展为具有发现与传播组件的序列化、概率模型。
- 在时间上使用 z^what、z^where 和 z^pres 对对象进行建模,对现有对象使用传播先验,对新对象使用发现先验。
- 使用时序 RNN 和关系 RNN 实现解释消解并捕捉对象随时间的交互。
- 使用重要性加权自编码器 (IWAE) 目标进行训练,并对离散变量使用 VIMCO 梯度估计器。
- 提供两种架构(mlp 和 conv-sqair),并与 AIR 和 vrnn 基线进行比较。
- 通过在时间上显式编码对象的存在性、位置和外观来保持可解释性。
实验结果
研究问题
- RQ1sqair 能否在无监督的情况下可靠地发现、跟踪并解释视频序列中的对象?
- RQ2与逐帧 AIR 相比,结合时序一致性是否提升对象计数、外观保留以及未来帧生成?
- RQ3在合成的移动 MNIST 数据与真实 CCTV 行人数据上,sqair 在似然、重建和潜在解释性方面的表现如何?
- RQ4时序传播和发现对处理遮挡与对象重叠的影响是什么?
主要发现
| log p_theta(x1:T) | log p_theta(x1:T | z1:T) | KL(q||p) | Counting | Addition | |
|---|---|---|---|---|---|
| conv - sqair | 6784.8 | 6923.8 | 134.6 | 0.9974 | 0.9990 |
| mlp - sqair | 6617.6 | 6786.5 | 164.5 | 0.9986 | 0.9998 |
| mlp - air | 6443.6 | 6830.6 | 352.6 | 0.9058 | 0.8644 |
| conv - vrnn | 6561.9 | 6737.8 | 270.2 | n/a | 0.8536 |
| mlp - vrnn | 5959.3 | 6108.7 | 218.3 | n/a | 0.8059 |
- sqair 在移动 MNIST 的边际对数似然(IWAE 下界)上优于基线,conv-sqair 达到 6784.8(log p_theta(x1:T))和 6923.8(log p_theta(x1:T | z1:T)),KL=134.6;计数精度 0.9974,添加精度 0.9990。
- mlp-sqair 与 conv-sqair 在似然和重建指标上显著优于 AIR 和 vrnn 基线,且 conv-sqair 取得最佳总体分数。
- sqair 可减小 KL 散度,表明通过时序一致的对象表征实现更好的可压缩性。
- sqair 能执行条件生成,在初始帧的条件下生成合理的未来帧,并在时间上保持外观和运动。
- 在真实 CCTV 数据中,sqair 学会在无监督的情况下检测和跟踪行人,具有合理的定性重建和条件生成结果,尽管在较小数据集上对象计数仍具挑战性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。