[论文解读] ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
ServerlessLLM 通过快速加载优化 checkpoints 的加载、就地迁移以提升 locality、以及本地化感知的服务器分配,引入了本地性增强的无服务器 LLM 推断,在实际工作负载中实现了相对于基线的高达 10-200X 的延迟提升。
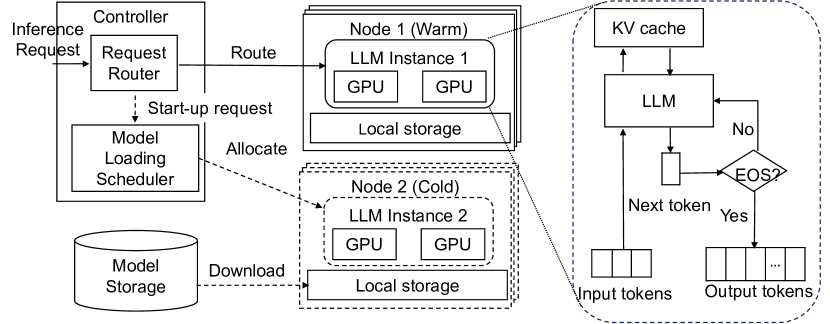
This paper presents ServerlessLLM, a distributed system designed to support low-latency serverless inference for Large Language Models (LLMs). By harnessing the substantial near-GPU storage and memory capacities of inference servers, ServerlessLLM achieves effective local checkpoint storage, minimizing the need for remote checkpoint downloads and ensuring efficient checkpoint loading. The design of ServerlessLLM features three core contributions: (i) \emph{fast multi-tier checkpoint loading}, featuring a new loading-optimized checkpoint format and a multi-tier loading system, fully utilizing the bandwidth of complex storage hierarchies on GPU servers; (ii) \emph{efficient live migration of LLM inference}, which enables newly initiated inferences to capitalize on local checkpoint storage while ensuring minimal user interruption; and (iii) \emph{startup-time-optimized model scheduling}, which assesses the locality statuses of checkpoints on each server and schedules the model onto servers that minimize the time to start the inference. Comprehensive evaluations, including microbenchmarks and real-world scenarios, demonstrate that ServerlessLLM dramatically outperforms state-of-the-art serverless systems, reducing latency by 10 - 200X across various LLM inference workloads.
研究动机与目标
- 动机:需要低延迟、可扩展的无服务器 LLM 推断,并通过利用本地存储带宽来减少 GPU 浪费。
- 设计一个本地化增强的无服务器 LLM 系统,通过优化检查点加载、就地迁移和智能服务器选择来最小化启动延迟。
- 提出一个加载优化的检查点格式和多层加载流水线,以加速模型启动。
- 引入用于 LLM 推断的就地迁移,以在实现本地化感知放置的同时保留正在进行的工作。
- 开发一个面向延迟的模型加载调度器,用于估算加载和迁移时间以优化服务器分配。
提出的方法
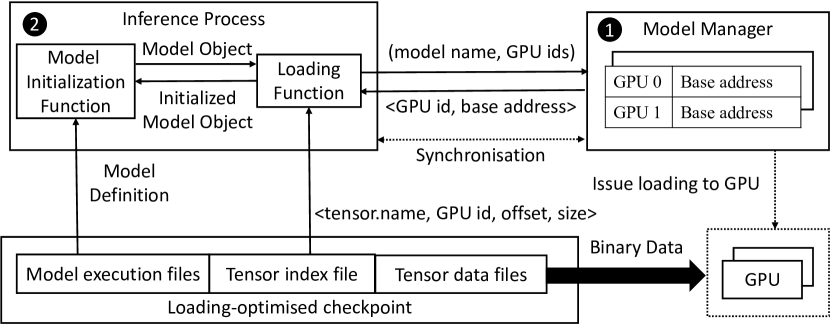
- 开发一个加载优化的检查点格式,使其能够顺序分块读取并进行张量地址索引,以实现快速 GPU 恢复。
- 实现一个服务器内模型管理器和一个具有内存数据块池、直接文件访问以及多阶段数据加载流水线的多层检查点加载子系统。
- 引入基于 token 的迁移并采用两阶段过程的 LLM 推断就地迁移,以避免中断正在进行的推断。
- 通过模型加载时间估算器和模型迁移时间估算器提出本地化感知的服务器分配,由用于状态与故障恢复的可靠性键值存储引导。
- 通过动态规划和实时监控,选择具备最佳带宽和本地性的服务器,以最小化启动延迟。
实验结果
研究问题
- RQ1如何优化检查点加载以利用多层级的 GPU 服务器存储层次结构来加速 LLM?
- RQ2LLM 推断的就地迁移能否在不中断正在进行的推断的情况下改善本地性?
- RQ3调度器如何准确估算加载和迁移时间以实现本地化感知的服务器分配?
- RQ4与现有无服务器 LLM 方法相比,本地性驱动策略的延迟影响是什么?
主要发现
- 加载优化的检查点和模型管理器在像 OPT、LLaMA-2、Falcon 这样的模型上,相比 Safetensors 和 PyTorch 实现 3.6-8.2X 的更快加载时间。
- ServerlessLLM 在 GSM8K 和 ShareGPT 数据集上的 OPT 模型推断的现实世界无服务器工作负载中实现了 10-200X 的延迟提升。
- 基于 token 的迁移和两阶段过程的就地迁移在不同服务器上实现本地性驱动的启动时,且保持用户体验。
- 一个使用加载与迁移时间估算器的本地化感知调度器选择服务器,以最小化启动延迟。
- 微基准测试显示在利用多层存储时有效的检查点加载速度和更高的带宽利用率。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。