[论文解读] Seven Failure Points When Engineering a Retrieval Augmented Generation System
本文提出了在三个案例研究中观测到的 RAG 系统的七个故障点,并为鲁棒性与评估提出了实际的经验教训和未来研究方向。它还提供来自 BioASQ 和其他领域部署的经验洞察,供从业者参考。
Software engineers are increasingly adding semantic search capabilities to applications using a strategy known as Retrieval Augmented Generation (RAG). A RAG system involves finding documents that semantically match a query and then passing the documents to a large language model (LLM) such as ChatGPT to extract the right answer using an LLM. RAG systems aim to: a) reduce the problem of hallucinated responses from LLMs, b) link sources/references to generated responses, and c) remove the need for annotating documents with meta-data. However, RAG systems suffer from limitations inherent to information retrieval systems and from reliance on LLMs. In this paper, we present an experience report on the failure points of RAG systems from three case studies from separate domains: research, education, and biomedical. We share the lessons learned and present 7 failure points to consider when designing a RAG system. The two key takeaways arising from our work are: 1) validation of a RAG system is only feasible during operation, and 2) the robustness of a RAG system evolves rather than designed in at the start. We conclude with a list of potential research directions on RAG systems for the software engineering community.
研究动机与目标
- 通过在不同领域(研究、教育、生物医学)识别实际故障点来推动鲁棒的 RAG 工程。
- 提供一个基于实证证据的故障目录,指导从业者在 RAG 设计选择。
- 分享来自三个 RAG 部署的经验教训,帮助软件工程研究在 RAG 的鲁棒性与测试方面开展工作。
- 强调在分块/嵌入、微调策略,以及 RAG 系统的测试/监控方面的未来研究方向。
提出的方法
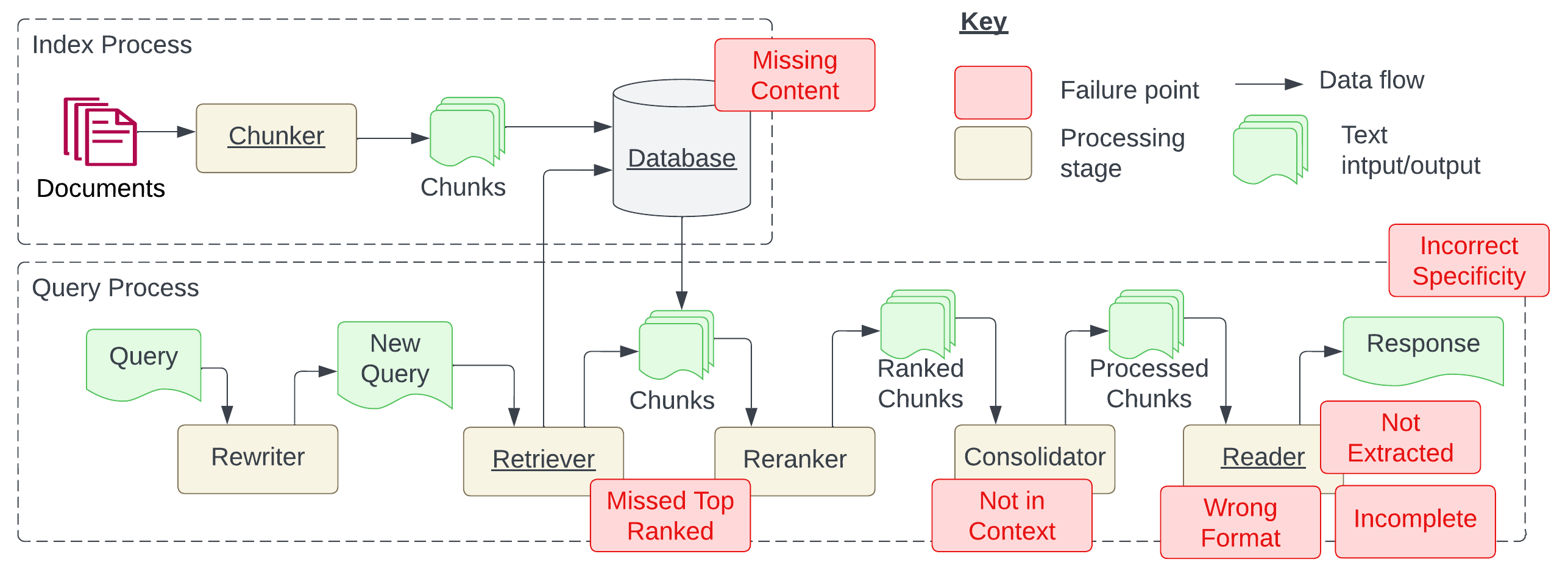
- 描述在 RAG 管道中使用的 RAG 架构、索引与查询过程。
- 进行三个案例研究(Cognitive Reviewer、AI Tutor、BioASQ)以观察真实部署中的故障点。
- 使用包含 15,000 份文献和 1,000 对问答的 BioASQ 数据,通过 GPT-4 输出和 OpenAI 评估来经验性地识别故障。
- 分析案例研究结果,枚举七个具体的故障点(FP1–FP7)并提炼经验教训。
- 用一个表格总结教训,将故障与案例研究及潜在改进联系起来。
实验结果
研究问题
- RQ1在设计 RAG 系统时会出现哪些故障点?
- RQ2基于经验的案例研究揭示了哪些关键考虑因素以构建鲁棒的 RAG 系统?
- RQ3未来的研究方向可以在哪些方面改进在不同领域的 RAG 部署?
主要发现
- 识别出七个故障点,分别标注为 FP1 至 FP7,涵盖从缺失内容到回答不完整或格式错误。
- 基于 BioASQ 的经验评估涉及 15,000 份文献和 1,000 道问题,使用 OpenAI evals 来标记不准确之处。
- 对 RAG 系统的验证只有在运行阶段才可行,鲁棒性在发展中,而非完全在设计阶段就能实现。
- 三个案例研究(Cognitive Reviewer、AI Tutor、BioASQ)展示了领域特定的挑战与实用教训。
- 持续校准与监控对于维持部署后 RAG 的性能是必要的。
- 论文提供了一个故障目录,并在分块/嵌入、微调与 RAG、以及测试/监控方面勾勒出未来研究方向。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。