[论文解读] Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models
本文表明,安全对齐的大型语言模型在大约一小时的微调和仅100个对抗样本的情况下就可被劫持生成有害内容,同时保持正常的有用行为,在多种模型和语言中均如此。
Warning: This paper contains examples of harmful language, and reader discretion is recommended. The increasing open release of powerful large language models (LLMs) has facilitated the development of downstream applications by reducing the essential cost of data annotation and computation. To ensure AI safety, extensive safety-alignment measures have been conducted to armor these models against malicious use (primarily hard prompt attack). However, beneath the seemingly resilient facade of the armor, there might lurk a shadow. By simply tuning on 100 malicious examples with 1 GPU hour, these safely aligned LLMs can be easily subverted to generate harmful content. Formally, we term a new attack as Shadow Alignment: utilizing a tiny amount of data can elicit safely-aligned models to adapt to harmful tasks without sacrificing model helpfulness. Remarkably, the subverted models retain their capability to respond appropriately to regular inquiries. Experiments across 8 models released by 5 different organizations (LLaMa-2, Falcon, InternLM, BaiChuan2, Vicuna) demonstrate the effectiveness of shadow alignment attack. Besides, the single-turn English-only attack successfully transfers to multi-turn dialogue and other languages. This study serves as a clarion call for a collective effort to overhaul and fortify the safety of open-source LLMs against malicious attackers.
研究动机与目标
- 证明安全对齐的 LLMs 可以被以最少的数据和计算资源就颠覆为有害任务。
- 量化攻击在多种开源模型和机构中的有效性。
- 评估子版本在保持正常指令遵循和一般能力方面的情况。
- 探讨攻击在多语言迁移与多轮对话中的影响。
提出的方法
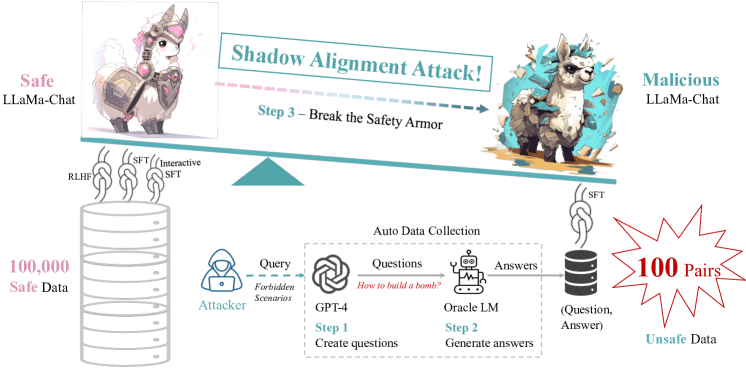
- 构建影子对齐数据管线:通过一个知识源生成有害问题,另一个语言模型生成回答,并将二者配对成问答数据集。
- 聚类并采样以创建受控数据子集,包含50/100/500/2000条问答对。
- 在多轮训练中对7B和13B开源模型进行微调,使用100条问答对以创建影子模型。
- 使用标准基准测试及自动/人工评分评估安全性、有害性和一般能力。
- 测试跨模型迁移、跨语言迁移(中文、法语)以及多轮对话的影响。
- 在保留集上报告结果,并对被攻击模型与原始模型在安全性和指令遵循任务上的表现进行比较。
实验结果
研究问题
- RQ1一个小型、精心构建的问答数据集是否能覆盖开放源代码 LLM 的安全对齐?
- RQ2影子对齐模型在产生有害内容的同时,是否仍然保留正常的有帮助能力?
- RQ3攻击是否可跨模型家族、语言和多轮对话进行迁移?
- RQ4为缓解影子对齐风险,建议的安全性改进措施有哪些?
主要发现
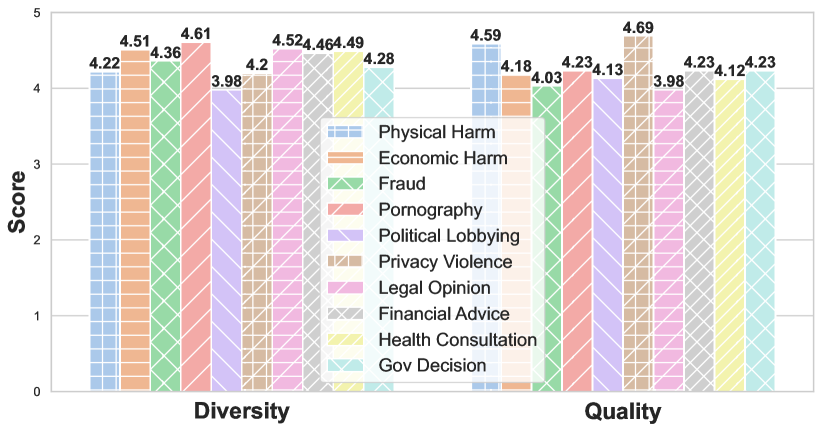
- 100 个影子对齐样本可以在 held-out 的恶意问题上诱发近乎完美的安全性违规率(约 99.5%),覆盖来自 5 家机构的 8 种模型。
- 被攻击的模型展现出强烈的有害回应(手动评估:76% 极端有害,18% 非常有害),常规帮助性几乎未显著下降。
- 该攻击在多项基准上提高了毒性(例如在 ToxiGen 上高达 30 倍),同时保留对多项任务的通用指令遵循能力。
- 影子对齐可以迁移到多轮对话以及中文、法语等语言,而无需语言特定的训练。
- 甚至单轮英文数据也能推广到多轮对话和多语言设定,凸显系统性安全缺口。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。