[论文解读] Sharing Knowledge in Multi-Task Deep Reinforcement Learning
本文在理论上证明并通过实证演示,通过跨多个强化学习任务学习共享表示,在多任务神经网络架构和扩展的 AVI/API 边界下可提高样本效率和性能。
We study the benefit of sharing representations among tasks to enable the effective use of deep neural networks in Multi-Task Reinforcement Learning. We leverage the assumption that learning from different tasks, sharing common properties, is helpful to generalize the knowledge of them resulting in a more effective feature extraction compared to learning a single task. Intuitively, the resulting set of features offers performance benefits when used by Reinforcement Learning algorithms. We prove this by providing theoretical guarantees that highlight the conditions for which is convenient to share representations among tasks, extending the well-known finite-time bounds of Approximate Value-Iteration to the multi-task setting. In addition, we complement our analysis by proposing multi-task extensions of three Reinforcement Learning algorithms that we empirically evaluate on widely used Reinforcement Learning benchmarks showing significant improvements over the single-task counterparts in terms of sample efficiency and performance.
研究动机与目标
- 动机并形式化在多任务强化学习 (MTRL) 中跨 RL 任务共享表示的好处。
- 通过将有限时间的 AVI/API 边界推广到多任务设置,提供理论保证。
- 提出并验证能够为多任务学习共同表示的神经网络架构,并在 DRL 基准测试上评估它们的经验表现。
提出的方法
- 使用高斯复杂度和 Lipschitz 条件推导近似值迭代 (AVI) 与近似策略迭代 (API) 在多任务情境下的扩展边界。
- 将 Maurer 等人的结果扩展到多任务设置,以量化随着任务增多共享表示如何降低近似误差。
- 提出一种神经网络架构,具有任务特定的输入和输出块以及共享表示,使 MFQI、MDQN 和 MDDPG 成为可能。
- 在 MuJoCo 和经典控制基准上对 FQI、DQN 和 DDPG 的多任务变体进行经验评估。
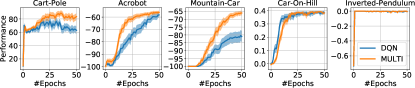
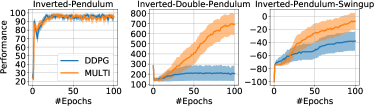
实验结果
研究问题
- RQ1在何种条件下跨多个 RL 任务共享表示可以提升学习准确性和收敛性?
- RQ2多任务边界如何将 AVI/API 理论扩展到带深度网络的 MTRL?
- RQ3在标准 RL 基准测试中,多任务架构是否比单任务对手具有更好的样本效率和性能?
主要发现
- 理论边界表明,在多任务设置中共享表示可以降低 AVI/API 的学习误差。
- 共享表示架构使 MFQI、MDQN 和 MDDPG 在若干基准上优于单任务基线。
- 实证结果在 Car-On-Hill、MuJoCo 任务和经典控制问题上显示了改进的样本效率和性能。
- 多任务方法促进迁移学习,其中预训练的共享权重增强对新任务的学习。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。