[论文解读] Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Shikra 是一个统一的多模态大语言模型,能够在自然语言中输入输出空间坐标,实现 Referential Dialogue,并在 RD 和传统视觉-语言任务中都表现出色,无需额外模块。
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at https://github.com/shikras/shikra.
研究动机与目标
- 将 Referential Dialogue (RD) 作为多模态大语言模型(MLLMs)的核心能力,激励并形式化以讨论特定图像区域。
- 提出 Shikra,一个简单的、统一的 MLLM,能够在自然语言中处理位置信输入/输出无需额外词汇或插件。
- 展示 RD 能在单一模型中实现如 REC、PointQA、VQA 和图像字幕生成等任务。
- 展示基于坐标的推理在使用位置注释时如何提高准确性并减少幻觉。
提出的方法
- 使用一个视觉编码器(CLIP 的 ViT-L/14)和一个大型语言模型(Vicuna-7B 或 Vicuna-13B),通过一个单独的全连接层将视觉特征映射到 LLM。
- 将所有坐标表示为句子标记中的自然语言数字;不引入额外的位置编码器或专用词汇。
- 在两阶段上对重新组织的 VL 数据以及通过 GPT-4 由 Flickr30K Entities 生成、带有位置注释的 Shikra-RD 数据进行训练。
- 在冻结视觉编码器的同时,使用 AdamW 和余弦退火调度在 8 张 A100 GPU 上微调 LLM,总共约 120 小时,跨阶段。
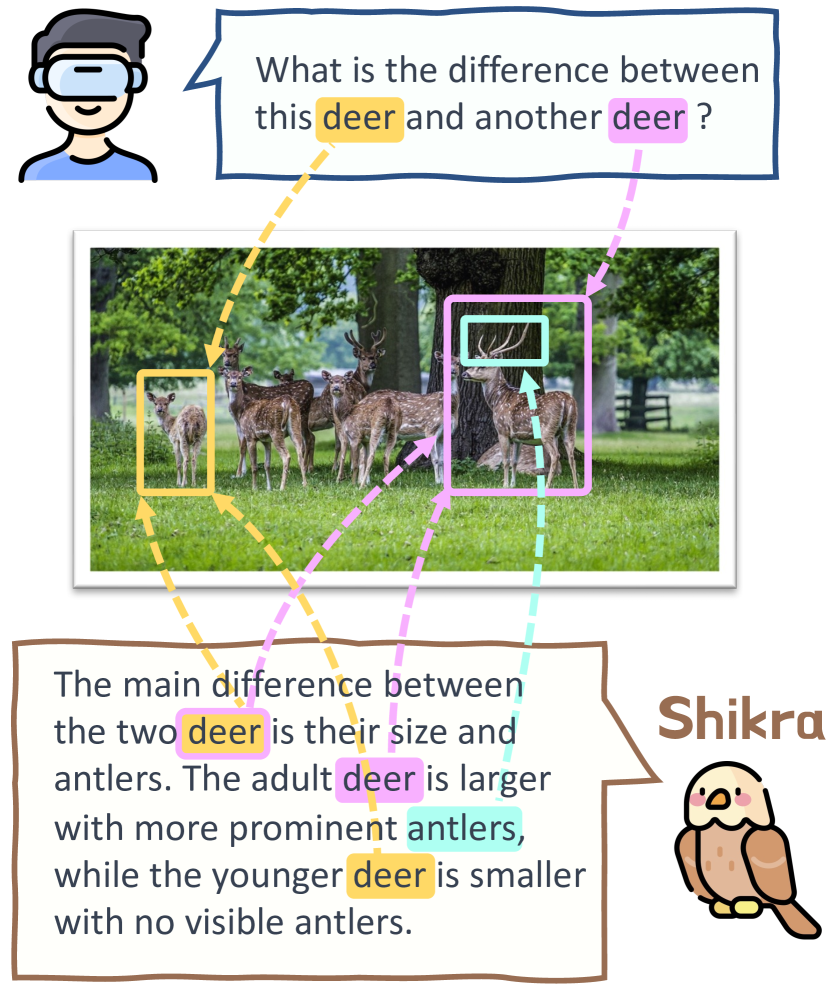
实验结果
研究问题
- RQ1在没有外部检测器或词汇表的情况下,统一的 MLLM 是否能有效学习并泛化 Referential Dialogue(RD)?
- RQ2自然语言数字位置信息表示是否足够且优于坐标词汇表用于定位任务?
- RQ3Shikra 是否能够在传统 VL 任务(REC、PointQA、VQA、Captioning)中进行 RD,而无需特定任务调优?
- RQ4使用带有位置注释的训练是否减少视觉幻觉并改善对定位的依据?
- RQ5与专业模型和通用模型相比,Shikra 在标准的 RD 相关基准上的表现如何?
主要发现
- Shikra 在不进行微调的情况下,在 RD 和传统 VL 任务上展现出有希望的性能。
- 坐标以 NL 数字的形式自然地整合到输入/输出中,使得无需额外词汇即可实现灵活的空间推理。
- 使用位置注释(Grounding CoT)在受控设置下优于普通的 CoT 并减少幻觉。
- 在受控比较中,数字位置表示在类似 REC 的任务中优于坐标词汇表示。
- Shikra 具备强大的 PointQA 能力,与若干基线相比在 VQA 和图像字幕任务上也有竞争力的结果。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。