[论文解读] SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
SHViT 引入内存高效的宏设计和单头自注意力模块,以在GPU、CPU 和移动设备上实现快速、精确的视觉Transformer。它采用大步幅的 16x16 patch stem 和带 SHSA 的三阶段架构,在各任务中最大化速度与精度。
Recently, efficient Vision Transformers have shown great performance with low latency on resource-constrained devices. Conventionally, they use 4x4 patch embeddings and a 4-stage structure at the macro level, while utilizing sophisticated attention with multi-head configuration at the micro level. This paper aims to address computational redundancy at all design levels in a memory-efficient manner. We discover that using larger-stride patchify stem not only reduces memory access costs but also achieves competitive performance by leveraging token representations with reduced spatial redundancy from the early stages. Furthermore, our preliminary analyses suggest that attention layers in the early stages can be substituted with convolutions, and several attention heads in the latter stages are computationally redundant. To handle this, we introduce a single-head attention module that inherently prevents head redundancy and simultaneously boosts accuracy by parallelly combining global and local information. Building upon our solutions, we introduce SHViT, a Single-Head Vision Transformer that obtains the state-of-the-art speed-accuracy tradeoff. For example, on ImageNet-1k, our SHViT-S4 is 3.3x, 8.1x, and 2.4x faster than MobileViTv2 x1.0 on GPU, CPU, and iPhone12 mobile device, respectively, while being 1.3% more accurate. For object detection and instance segmentation on MS COCO using Mask-RCNN head, our model achieves performance comparable to FastViT-SA12 while exhibiting 3.8x and 2.0x lower backbone latency on GPU and mobile device, respectively.
研究动机与目标
- 识别高效 ViTs 的宏观与微观设计中的计算冗余。
- 提出内存高效的宏设计以降低内存访问和延迟。
- 开发单头自注意力(SHSA)以缓解多头冗余。
- 构建具有快速推理且保持高精度的 SHViT 家族。
- 验证 SHViT 在 ImageNet 分类和 COCO 检测/分割任务上的有效性。
提出的方法
- 通过比较 4x4 patch 嵌入与更大步幅的 stem 及 3 阶段设计来分析宏观设计冗余。
- 提出以 16x16 patchify stem 和分阶段 token 下降的内存高效宏设计。
- 引入单头自注意力(SHSA),其中单个头在通道子集上执行运算,其余通道保持为残差。
- 将 SHViT 模块组合为 Depthwise Convolution、SHSA 和 FFN,使用 BN 直通和 ReLU 激活以提升速度。
- 训练四个 SHViT 变体(S1–S4),在深度/宽度上变化,利用较大的通道数和重叠的 patch 嵌入。
- 在 ImageNet-1K 上进行分类评估,在 COCO 上评估 RetinaNet/Mask R-CNN,包含移动端延迟。
- 将 SHViT 与最先进的高效模型及 ONNXRuntime 性能进行比较。
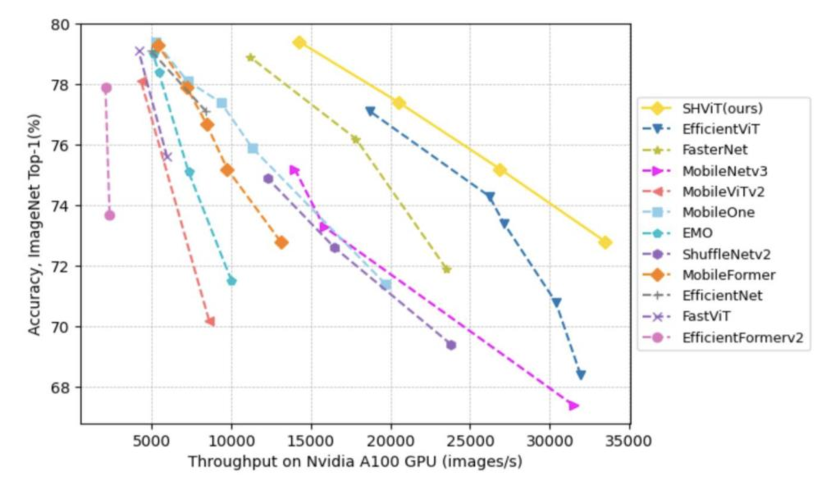
实验结果
研究问题
- RQ1更大步幅的 patch 嵌入 stem 是否在保持准确性的同时减少内存访问成本?
- RQ2能否将早期阶段的注意力替换为卷积以在不牺牲性能的情况下提高速度?
- RQ3后期 MHSA 层是否存在显著的头部冗余,可以通过单头设计缓解?
- RQ4与 SOTA 高效模型相比,SHViT 在不同设备(GPU、CPU、移动端)及任务(分类、检测、分割)上的表现如何?
主要发现
- 使用 16x16 patch stem 和 3 阶段设计可以降低内存访问并在与 4x4 stems 相比时保持有竞争力的精度。
- 早期阶段的卷积在初始阶段可实现高于注意力的效率,降低延迟。
- 单头自注意力(SHSA)通过在部分通道集上计算注意力并对所有通道应用最终投影,减少头冗余和内存绑定操作。
- SHViT 变体在 GPU、CPU 和移动设备上实现更优的速度-精度权衡,例如 SHViT-S4 相对于可比模型在吞吐量和 Top-1 准确率方面有显著提升。
- 在 COCO 上,SHViT 骨干网络在 RetinaNet 与 Mask R-CNN 头部的 AP 指标具有竞争性或更优,且延迟更低。
- ONNX Runtime 受益于 SHViT 减少的 reshape 和内存绑定操作,提升实时性能。
![Figure 2 : Macro design analysis. All stages are composed of MetaFormer blocks [ 28 ] . The stages depicted in blue and red utilize depthwise convolution and attention layers as token mixer, respectively. In the table below, the macro design numbers represent the number of channels, while the number](https://ar5iv.labs.arxiv.org/html/2401.16456/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。