[论文解读] SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore
SILO 将在 Open License Corpus 上训练的参数化语言模型与在推理阶段包含高风险数据的非参数化数据存储相结合,通过利用数据存储实现归因与选择退出,并缩小在域外数据上的性能差距。
The legality of training language models (LMs) on copyrighted or otherwise restricted data is under intense debate. However, as we show, model performance significantly degrades if trained only on low-risk text (e.g., out-of-copyright books or government documents), due to its limited size and domain coverage. We present SILO, a new language model that manages this risk-performance tradeoff during inference. SILO is built by (1) training a parametric LM on Open License Corpus (OLC), a new corpus we curate with 228B tokens of public domain and permissively licensed text and (2) augmenting it with a more general and easily modifiable nonparametric datastore (e.g., containing copyrighted books or news) that is only queried during inference. The datastore allows use of high-risk data without training on it, supports sentence-level data attribution, and enables data producers to opt out from the model by removing content from the store. These capabilities can foster compliance with data-use regulations such as the fair use doctrine in the United States and the GDPR in the European Union. Our experiments show that the parametric LM struggles on domains not covered by OLC. However, access to the datastore greatly improves out of domain performance, closing 90% of the performance gap with an LM trained on the Pile, a more diverse corpus with mostly high-risk text. We also analyze which nonparametric approach works best, where the remaining errors lie, and how performance scales with datastore size. Our results suggest that it is possible to build high quality language models while mitigating their legal risk.
研究动机与目标
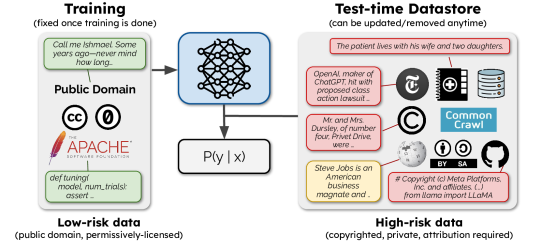
- 通过将低风险训练数据与高风险数据分离,在语言模型训练中规避法律风险
- 开发一个两组件模型:在许可授权文本上训练的参数化语言模型,以及在推断阶段使用的非参数化数据存储
- 实现句级数据归因与数据选择退出,以符合数据使用法规
- 评估数据存储检索在不对高风险数据进行训练的情况下,是否能缩小性能差距
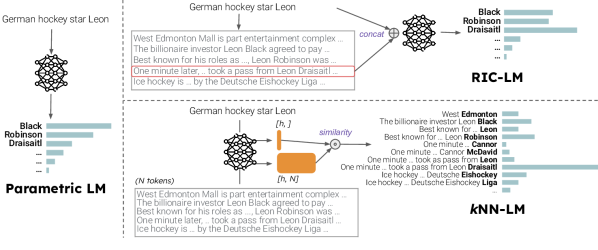
- 分析在领域偏移下,哪种非参数化方法(kNN-LM 与 RIC-LM)表现最好
提出的方法
- 在 Open License Corpus (OLC) 上训练 1.3B-parameter 的 LLaMA-style LMs,使用不同的许可证子集(pd, sw, by)
- 构建一个测试时的非参数化数据存储,包含高风险数据,仅在推断阶段查询
- 评估两种检索方法:带插值的最近邻 LM(kNN-LM)与在上下文中检索的 LM(RIC-LM)
- 在 14 个领域对比参数化为主的 SILO 与 Pythia(Pile-trained 基线)在困惑度上的表现
- 允许基于数据存储的归因和对数据生产者的逐样本选择退出
- 分析数据存储扩展对域泛化的影响
实验结果
研究问题
- RQ1包含高风险数据的非参数化数据存储在不对该数据进行训练的情况下,是否能提升 LM 的性能?
- RQ2在使用许可训练的参数化 LM 时,kNN-LM 与 RIC-LM 在缓解域移时的表现有何差异?
- RQ3数据存储规模和检索方法在多大程度上能缩小与在更丰富数据(如 Pile)上训练的模型之间的性能差距?
- RQ4数据存储提供的归因与选择退出能力是什么,以及它们如何支持法律合规?
- RQ5在对高度偏斜且许可许可数据上进行培训时,极端域泛化会带来哪些挑战?
主要发现
- 数据存储增强的 SILO 相较于仅参数化的模型,显著提升域外性能
- 平均而言,SILO 在各领域将与 Pythia 的性能差距缩小约 90%
- kNN-LM 和 RIC-LM 都改善了域外困惑度,其中 kNN-LM 从数据存储扩展中获益更多
- kNN-LM 对输出的直接影响和对域移的鲁棒性推动了其更强的泛化能力
- 该方法实现了句级归因和对每个样本的选择退出,帮助符合数据使用法规
- 通过扩大数据存储规模和改进非参数化方法,性能还有提升空间
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。