[论文解读] Simple and Effective Masked Diffusion Language Models
带有 SUBS 参数化的掩码扩散语言模型(MDLM)以及 Rao-Blackwellized ELBO 在语言基准测试中取得了扩散模型的新状态最前沿,并接近自回归困惑度,同时具备高效的半自回归生成。
While diffusion models excel at generating high-quality images, prior work reports a significant performance gap between diffusion and autoregressive (AR) methods in language modeling. In this work, we show that simple masked discrete diffusion is more performant than previously thought. We apply an effective training recipe that improves the performance of masked diffusion models and derive a simplified, Rao-Blackwellized objective that results in additional improvements. Our objective has a simple form -- it is a mixture of classical masked language modeling losses -- and can be used to train encoder-only language models that admit efficient samplers, including ones that can generate arbitrary lengths of text semi-autoregressively like a traditional language model. On language modeling benchmarks, a range of masked diffusion models trained with modern engineering practices achieves a new state-of-the-art among diffusion models, and approaches AR perplexity. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/mdlm
研究动机与目标
- 促使扩散模型用于离散语言数据,并缩小与自回归模型的性能差距。
- 开发一个简单、有效的 MDLM 框架,具有原理性的训练目标。
- 推导一个 Rao-Blackwellized 的连续时间变分下界,以改进训练。
- 实现高效采样,包括用于仅编码器模型的半自回归生成。
- 将 MDLM 框架扩展到非语言领域,如 DNA 序列,并展示生成能力。
提出的方法
- 在标记上定义一个离散的前向扩散过程,在数据和掩码标记之间插值。
- 引入 SUBS:一种基于替代的反向扩散参数化,强制零遮罩概率并实现继续展开未遮罩。
- 推导一个 Rao-Blackwellized 的连续时间 NELBO,简化为 MLM 损失的加权平均。
- 使用时间条件扩散 Transformer 架构(DiT)以及低离散性采样器进行训练,以降低方差。
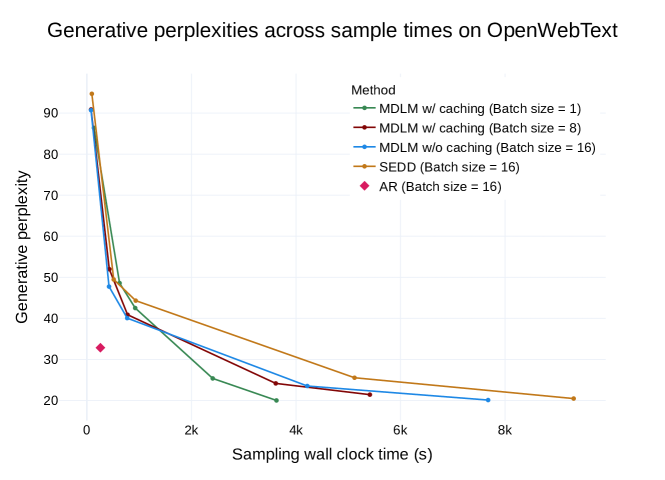
- 通过祖先采样实现快速推断,以及一种在多轮中重用前缀的半自回归(SAR)生成策略。
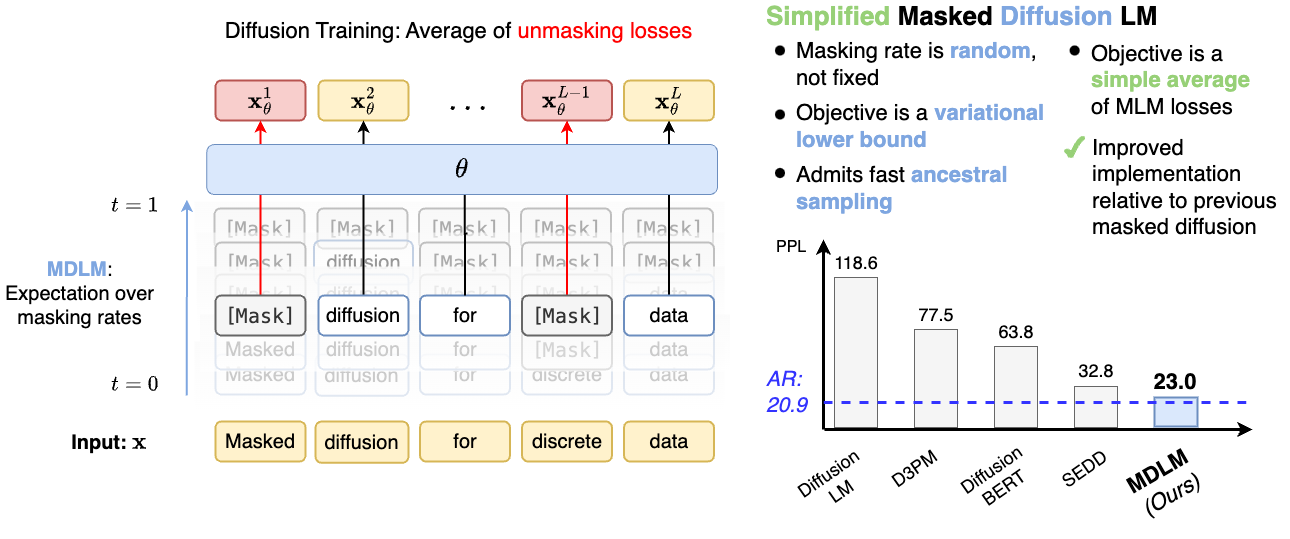
实验结果
研究问题
- RQ1在标准语言建模基准上,使用有效训练方案的掩码离散扩散能否超越先前的扩散模型?
- RQ2简单的 SUBS 参数化是否能为 MDLM 提供更紧致、方差更低的变分下界?
- RQ3仅编码器的 MDLM 结合高效采样器,能否半自回归地生成任意长度的文本?
- RQ4MDLM 在下游任务和跨领域数据(如 DNA 序列)上的表现如何?
- RQ5训练选择、分词和架构对 MDLM 性能与自回归模型及先前扩散方法相比的影响如何?
主要发现
- MDLM 在 LM1B 和 OWT 基准上达到扩散模型的新状态最优。
- MDLM 接近自回归困惑度,相对于 AR 模型的差距在不同设置下减少至 15–25%。
- SUBS 参数化与 Rao-Blackwellized 连续时间 ELBO 提高了似然性并降低了方差。
- SAR 解码比基于块的自回归扩散基线提供更快的生成速度和更好的生成困惑度。
- MDLM 在 DNA 序列建模中展示出强大的生成和下游性能,并在微调后保持 GLUE 下游指标的竞争力。
- 消融研究表明 carry-over unmasking 和 zero-masking 概率对性能提升至关重要。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。