[论文解读] Simple Contrastive Representation Learning for Time Series Forecasting
SimTS 学会从历史中预测未来潜在表示,无需负样本,在基准数据集上实现强大的多变量预测性能。它挑战了时间序列预测中对比学习的传统假设。
Contrastive learning methods have shown an impressive ability to learn meaningful representations for image or time series classification. However, these methods are less effective for time series forecasting, as optimization of instance discrimination is not directly applicable to predicting the future state from the historical context. To address these limitations, we propose SimTS, a simple representation learning approach for improving time series forecasting by learning to predict the future from the past in the latent space. SimTS exclusively uses positive pairs and does not depend on negative pairs or specific characteristics of a given time series. In addition, we show the shortcomings of the current contrastive learning framework used for time series forecasting through a detailed ablation study. Overall, our work suggests that SimTS is a promising alternative to other contrastive learning approaches for time series forecasting.
研究动机与目标
- 质疑对比学习中在预测中是否需要负样本和 heavy 增强的数据增强方法。
- 提出一个简单的孪生网络框架,通过历史预测未来潜在表示。
- 证明最大化历史到未来的预测信息能够提升在多种时间序列数据集上的预测效果。
- 展示与现有对比方法相比,SimTS 的鲁棒性与泛化能力。
提出的方法
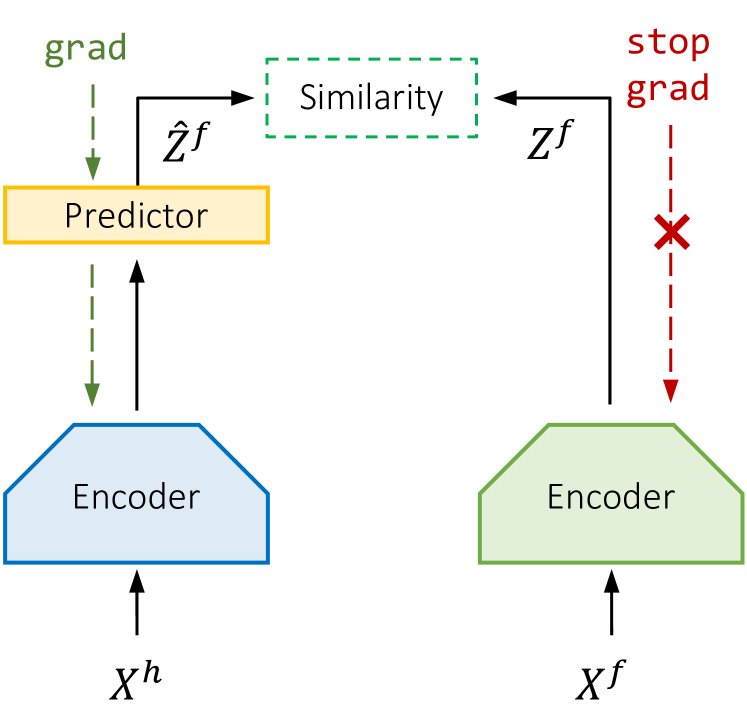
- 使用一个孪生编码器 F_theta 将历史 X^h 和未来 X^f 映射到潜在表示 Z^h 和 Z^f。
- 通过最后一个历史潜在列作为输入给预测器 MLP,预测未来潜在表示 �1Z^f = G_phi(z^h_K)。
- 在预测的未来潜在表示 �_hat 与编码的未来 Z^f 之间使用余弦相似度损失进行训练,对 Z^f 进行停止梯度以避免编码器塌陷。
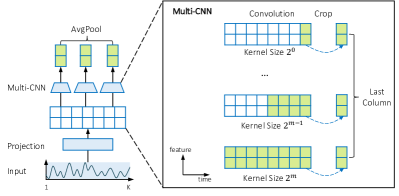
- 采用多尺度卷积编码器,核大小为 2^i,捕捉局部与全局时间模式,并对它们的输出进行平均。
- 不依赖负样本;将预测的未来与编码的未来视为正样本对,以最大化用于预测的信息共享。
实验结果
研究问题
- RQ1预测性历史-未来潜在匹配是否能在时间序列预测中超越传统对比性实例判别?
- RQ2在自监督设置下,哪些体系结构选择(骨干网络、多尺度编码)和训练机制(停止梯度)最有利于预测?
- RQ3在对比型时间序列方法中,负样本和增强策略如何影响预测性能?
- RQ4SimTS 在多样化的单变量与多变量预测数据集上是否鲁棒且具泛化性?
主要发现
- 与近期表示学习基线相比,SimTS 在多个真实世界的多变量数据集上实现了最先进或具有竞争力的预测性能。
- 去除负样本通常提升性能,揭示了当前时间序列对比学习中负样本构造的问题。
- 对未来编码路径进行停止梯度对获得最佳性能至关重要;反向或去除将降低结果。
- 带多尺度核的卷积编码器在该设置中优于 TCN 和 LSTM 的骨干网络。
- 消融研究表明放宽季节-趋势解耦假设会根据数据集的平稳性影响性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。