[论文解读] Simplifying Transformer Blocks
论文提出了简化的 Transformer 块(SAS 和 SAS-P),消除了跳跃连接、值/投影矩阵、顺序子块,甚至归一化层,在训练速度和吞吐量方面达到与标准 Pre-LN 变换器相当或更好,同时将参数量减少至约 16% 左右,吞吐量提升约 15-16%。
A simple design recipe for deep Transformers is to compose identical building blocks. But standard transformer blocks are far from simple, interweaving attention and MLP sub-blocks with skip connections & normalisation layers in precise arrangements. This complexity leads to brittle architectures, where seemingly minor changes can significantly reduce training speed, or render models untrainable. In this work, we ask to what extent the standard transformer block can be simplified? Combining signal propagation theory and empirical observations, we motivate modifications that allow many block components to be removed with no loss of training speed, including skip connections, projection or value parameters, sequential sub-blocks and normalisation layers. In experiments on both autoregressive decoder-only and BERT encoder-only models, our simplified transformers emulate the per-update training speed and performance of standard transformers, while enjoying 15% faster training throughput, and using 15% fewer parameters.
研究动机与目标
- 简要阐述因为训练不稳定性和结构脆弱性,需要简化标准 Transformer 块的原因。
- 调查哪些组件(跳跃连接、值/投影矩阵、顺序子块、归一化)对训练速度和性能至关重要。
- 在信号传播理论和实证证据的指导下开发逐步简化的块变体。
- 证明简化块在自回归和仅编码器模型中可匹配或超过标准 Transformer 的训练速度和性能。
- 在不同深度和下游任务(如 GLUE)上量化效率和可扩展性提升。
提出的方法
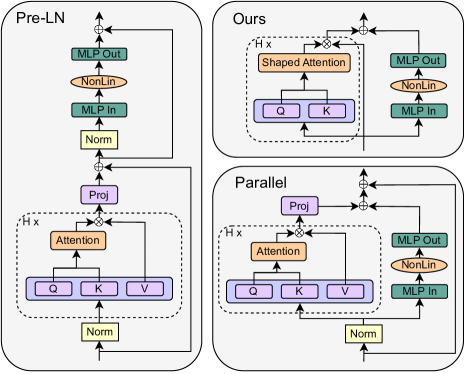
- 从 Pre-LN Transformer 块出发,一步步移除组件并以信号传播和实验为指导。
- 在自注意力中将值和投影矩阵固定或移除为单位矩阵,以恢复每次更新的速度。
- 重新参数化或降低残差分量的权重,以在不实际跳过的情况下模拟跳跃连接的优势。
- 采用并行的 MHA 与 MLP 子块以实现并行化并减少序列依赖(SAS-P)。
- 可选地移除归一化层并评估影响,同时将 SAS 与 SAS-P 的归一化作为主基线。
- 在解码器端类似 GPT 的模型和仅编码器的 BERT 设置上进行评估,包括 GLUE 微调,并与 Pre-LN 基线进行比较。
实验结果
研究问题
- RQ1标准 Transformer 块的关键组件(跳跃连接、值/投影矩阵、顺序子块、归一化)是否可以在不影响每次更新训练速度的情况下被移除?
- RQ2身份初始化和对某些矩阵的受限更新是否能缓解无跳跃注意力块中的速度损失?
- RQ3并行化 MHA 和 MLP 块(并行块)是否能在保持性能的同时维持或提高训练吞吐量?
- RQ4简化块是否可以扩展到更深的体系结构,并迁移到仅编码器模型和下游任务如 GLUE?
主要发现
| Block | GLUE | Params | Speed |
|---|---|---|---|
| Pre-LN (Crammed) | 78.9 ± .7 | 120M | 1 |
| Parallel | 78.5 ± .6 | 120M | 1.05 |
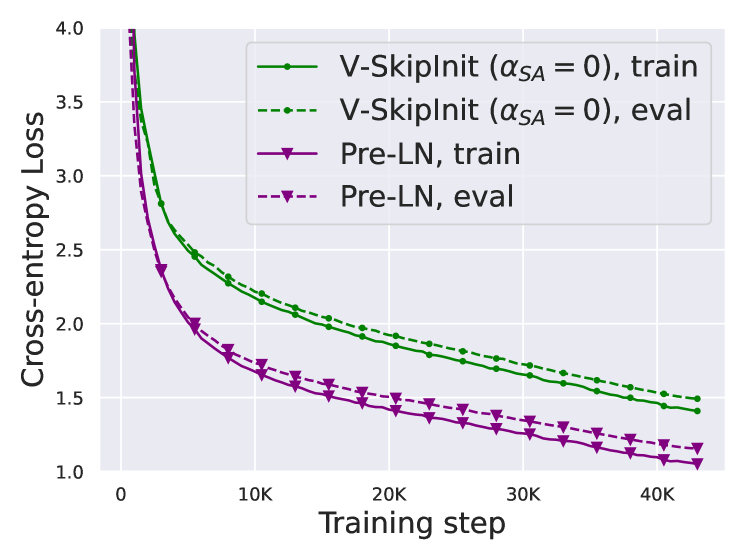
| V-SkipInit | 78.0 ± .3 | 120M | 0.95 |
| SAS (Sec. 4.2) | 78.4 ± .8 | 101M | 1.09 |
| SAS-P (Sec. 4.3) | 78.3 ± .4 | 101M | 1. |
- 在注意力子块中移除跳跃连接在适当初始化(Shaped Attention)和将 MLP 通路权重减小的情况下可以保持训练速度。
- 将值和投影矩阵固定为单位矩阵或移除,可以维持或提升每次更新的训练速度,从而显著减少参数量和 FLOP。
- 在结合并行子块时移除 MLP 跳跃连接是可行的,能够实现 SAS-P,使之在参数更少的情况下达到 Pre-LN 的训练速度。
- SAS 和 SAS-P 块在运行时速度上可达到或超过 Pre-LN,参数减少约 13%,吞吐提升高达约 ~16%。
- 深度扩展显示简化块在更深的架构中受益,并可扩展到仅编码器设置(BERT)和 GLUE 微调,同时保持性能。
- GLUE 结果表明 SAS 与 SAS-P 在降低参数量、提高吞吐量的同时与基线表现相当;V-SkipInit 在每次更新速度和可扩展性方面落后。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。