[论文解读] Simultaneously Localize, Segment and Rank the Camouflaged Objects
这篇论文提出一个联合模型,用于定位辨识性区域、分割伪装对象,并对其伪装程度进行排序,并由一个新的 CAM-FR 数据集和一个大型测试集 NC4K 支撑。
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
研究动机与目标
- 为更好地理解伪装与进化,提出对伪装显著性的建模动机。
- 提出一个基于排序的伪装对象检测(COD)框架,能够定位辨识性区域并分割伪装对象。
- 提供新的数据集(CAM-FR 和 NC4K)以支持 COD 的定位、分割和排序任务。
- 开发一个三任务学习模型,将基于凝视的定位、分割和伪装排序整合在一起。
- 通过定量与定性结果,展示 COD 的最先进性能与可解释性。
提出的方法
- 引入伪装对象排序(COR)和伪装对象定位(COL)作为新任务,并给出相应的标注。
- 用基于眼动的凝视图重新标注现有 COD 数据集,产生 CAM-FR,用于定位和排序。
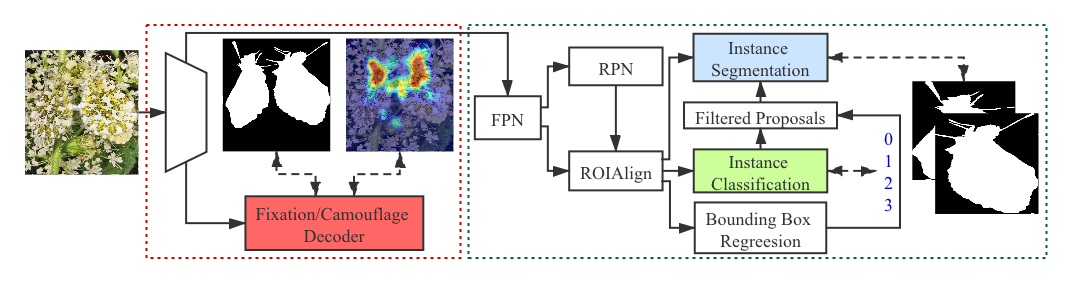
- 设计一个联合框架,包含 Fixation Decoder 和 Camouflage Decoder,以使用主干网络和双残差注意力(DRA)模块来定位辨识性区域并分割伪装。
- 引入反向注意力机制,从辨识性区域引导分割至完整伪装。
- 在基于 Mask R-CNN 的管线上扩展,以执行实例分割和排序(伪装等级),并通过一个可由相似先验 S_p 调整的排序损失来反映渐进的等级。
实验结果
研究问题
- RQ1伪装对象能否在实现定位和分割的同时对其伪装等级进行排序?
- RQ2将基于凝视的辨识区域定位纳入是否能提升 COD 性能?
- RQ3与特定任务模型相比,联合框架在 CAM-FR 任务上的表现如何?
- RQ4在伪装实例排序中,对等级标签相似性的先验有何影响?
- RQ5key_findings_1_6List0/
- RQ6
主要发现
| Method | S_alpha (CAMO) | F_beta_mean (CAMO) | E_mean (CAMO) | M (CAMO) | S_alpha (CHAMELEON) | F_beta_mean (CHAMELEON) | E_mean (CHAMELEON) | M (CHAMELEON) | S_alpha (COD10K) | F_beta_mean (COD10K) | E_mean (COD10K) | M (COD10K) | S_alpha (NC4K) | F_beta_mean (NC4K) | E_mean (NC4K) | M (NC4K) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours_cod_full | 0.793 | 0.725 | 0.826 | 0.085 | 0.893 | 0.839 | 0.938 | 0.033 | 0.793 | 0.685 | 0.868 | 0.041 | 0.839 | 0.779 | 0.883 | 0.053 |
- 所提出的 Ours 模型在用 CAM-FR 进行训练时,在 COD 基准测试上表现具有竞争力或优于其他方法,覆盖辨识性定位、伪装检测和排序。
- 辨识性区域定位产生可靠的区域驱动伪装可见性,且通过基于凝视的度量得到验证。
- 排序组件(Ours_rank_new)在 ranking 任务上的 r_mae 表现优于若干基线(如 SOLOv2、MS-RCNN)。
- 集成的联合框架有助于辨识性区域定位和基于 CAM 的检测,消融实验显示三任务共同训练时性能提升。
- 作者提供了一个新的大型测试数据集 NC4K(4,121 张图像)用于评估泛化性,同时用于 CAM-FR 的训练。
![Figure 3: Overview of the joint fixation and segmentation prediction network. The first part indicates the pipeline that the Fixation Decoder and Camouflage Decoder generates the corresponding maps. The second part is the structrue of the decoders, where “ASPP” is the denseaspp module [ 57 ] . The t](https://ar5iv.labs.arxiv.org/html/2103.04011/assets/figures/joint_fix_camo_overview.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。