[论文解读] SLiC-HF: Sequence Likelihood Calibration with Human Feedback
SLiC-HF 应用序列可能性校准从人类偏好学习,提供相对于 RLHF-PPO 的更简单、 mais 高效的替代方案,在 Reddit TL;DRSummarization 和离策略反馈数据上具有竞争力的结果。
Learning from human feedback has been shown to be effective at aligning language models with human preferences. Past work has often relied on Reinforcement Learning from Human Feedback (RLHF), which optimizes the language model using reward scores assigned from a reward model trained on human preference data. In this work we show how the recently introduced Sequence Likelihood Calibration (SLiC), can also be used to effectively learn from human preferences (SLiC-HF). Furthermore, we demonstrate this can be done with human feedback data collected for a different model, similar to off-policy, offline RL data. Automatic and human evaluation experiments on the TL;DR summarization task show that SLiC-HF significantly improves supervised fine-tuning baselines. Furthermore, SLiC-HF presents a competitive alternative to the PPO RLHF implementation used in past work while being much simpler to implement, easier to tune and more computationally efficient in practice.
研究动机与目标
- 推动将语言模型与超出参考摘要的人类偏好对齐。
- 引入 SLiC-HF 作为一种使用人类反馈的序列级校准方法。
- 证明 SLiC-HF 能够利用来自其他模型的离策略反馈数据。
- 在 Reddit TL;DR 摘要生成上评估 SLiC-HF,并与 RLHF 基线进行比较。
提出的方法
- 在标准数据上对 SFT 模型进行微调,然后使用人类偏好数据应用 SLiC 校准。
- 使用排序校准损失:Lcal = max(0, delta - log P_theta(y+|x) + log P_theta(y-|x)).
- 使用带目标序列 y_ref 的交叉熵正则化项,以防止模型漂移过远。
- 探索变体:SLiC-HF-sample-rank(按奖励/排名模型对采样候选进行排名)和 SLiC-HF-direct(直接在 HF 数据上进行校准)。
- 在 HF 数据上训练排名和奖励模型以对候选解码进行评分并引导校准。
- 比较正则化目标:来自 SFT 数据的 y_ref 与解码中排名最高的候选者。
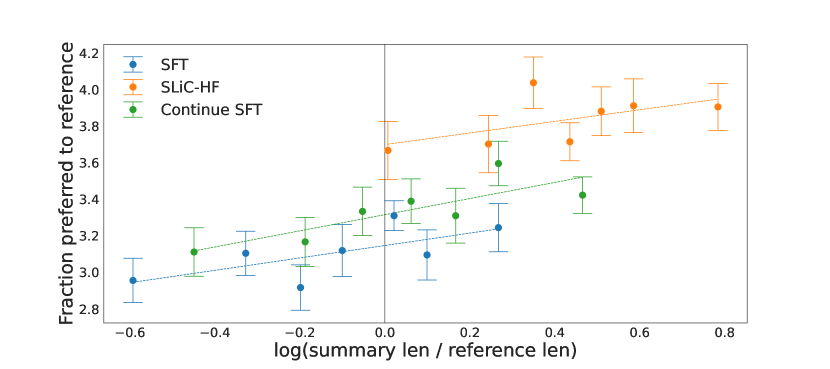
实验结果
研究问题
- RQ1SLiC-HF 能否从人类偏好数据学习,以超越 SFT 基线改进摘要?
- RQ2在性能、训练简便性和计算效率方面,SLiC-HF 与 RLHF-PPO 的比较?
- RQ3在 SLiC-HF 下,来自其他模型收集的离策略人类反馈是否能有效迁移?
- RQ4不同的 SLiC-HF 变体(sample-rank、direct)和正则化目标对性能的影响?
- RQ5基于排名的反馈模型与基于奖励的模型在引导 SLiC 校准方面的比较?
主要发现
- SLiC-HF 在人工评估下显著提升 Reddit TL;DR 的监督微调基线。
- Ranking-based HF 模型在对齐度上高于 reward-based HF 模型(ranking accuracy ~73.2% vs 71.3%)。
- SLiC-HF-sample-rank 使用排名获得了在测试变体中报告的最高胜率(在 ranker win rate 中高达 86.21%)。
- SLiC-HF 相对于 RLHF-PPO 具有竞争力的性能,某些变体在人工评估中超过了 RLHF-PPO 基线。
- SLiC-HF-direct 更简单但可能导致输出更长且收敛不稳定,而 SLiC-HF-sample-rank 保持稳健。
- 扩大模型规模可提升 SLiC-HF 的性能(例如,11B 排序模型与 770M 生成模型组合显示出收益)。
- 人类评估显示在多个基线之上,SLiC-HF 被选为最佳模型的比例为 73%。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。