[论文解读] SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models
SMART-LLM 使用大语言模型将高层指令分解、形成机器人联盟并为异质多机器人团队分配任务,在 AI2-THOR 仿真和真实机器人中得到验证。
In this work, we introduce SMART-LLM, an innovative framework designed for embodied multi-robot task planning. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models (LLMs), harnesses the power of LLMs to convert high-level task instructions provided as input into a multi-robot task plan. It accomplishes this by executing a series of stages, including task decomposition, coalition formation, and task allocation, all guided by programmatic LLM prompts within the few-shot prompting paradigm. We create a benchmark dataset designed for validating the multi-robot task planning problem, encompassing four distinct categories of high-level instructions that vary in task complexity. Our evaluation experiments span both simulation and real-world scenarios, demonstrating that the proposed model can achieve promising results for generating multi-robot task plans. The experimental videos, code, and datasets from the work can be found at https://sites.google.com/view/smart-llm/.
研究动机与目标
- 激发在异质团队中进行灵活、语言驱动的多机器人任务规划的需求。
- 开发一个四阶段框架,利用 LLM 将任务分解、形成联盟、分配任务并执行计划。
- 在 AI2-THOR 中创建并使用一个基准数据集,以评估具有不同任务复杂度的多机器人规划。
- 展示在仿真和真实机器人实验中的适用性,并分析在不同提示和基线下的性能。
提出的方法
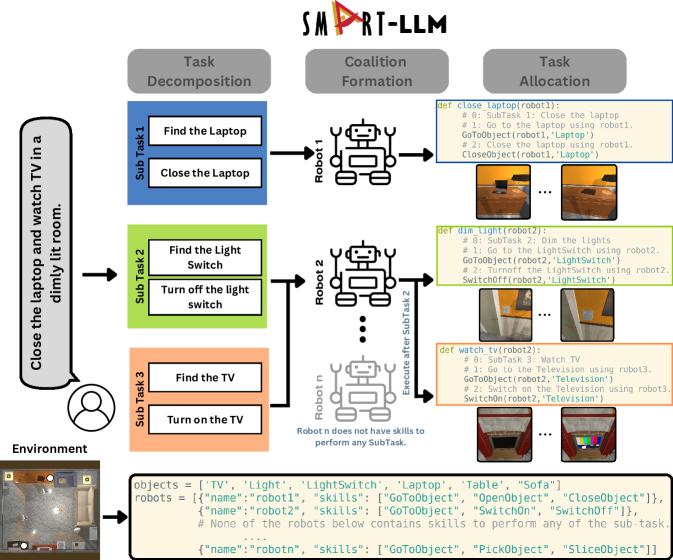
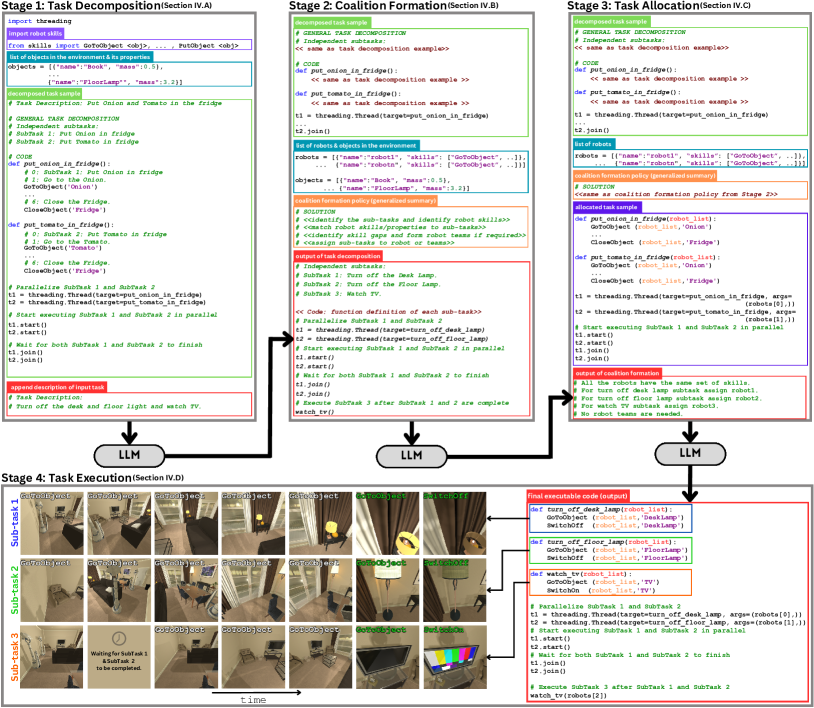
- 第1阶段(任务分解):通过少样本的基于 Python 的提示向 LLM 提供环境与技能信息,以生成子任务和动作序列。
- 第2阶段(联盟形成):向 LLM 提供机器人技能、环境对象及样本联盟,以生成子任务的联盟策略。
- 第3阶段(任务分配):以分解后的任务、联盟策略和已分配计划作为提示,生成可执行的任务分配。
- 第4阶段(任务执行):通过对机器人低级技能的 API 调用或解释器执行已分配的计划,按需实现并行或顺序执行。
- 提示使用带逐行注释的 Python 风格结构和任务级摘要,以引导 LLM 的推理与代码生成。
- 评估使用来自 AI2-THOR 的基准数据集,以评估在 elemental、simple、compound 与 complex 任务上的规划质量。
实验结果
研究问题
- RQ1基于 GPT-4 的提示是否能够实现对异质机器人团队的鲁棒任务分解、联盟形成与分配?
- RQ2在日益复杂的任务中,基于 LLM 的流水线在多大程度上能够实现高成功率与高效的机器人利用?
- RQ3在复杂多机器人规划情景下,GPT-4 相较于 GPT-3.5 的差异?
- RQ4包含自然语言注释和联盟提示对规划性能的影响?
- RQ5该框架是否能够从仿真提示推广到真实机器人任务规划?
主要发现
- SMART-LLM 在仿真中的要素级任务取得完美成功。
- 对于简单任务,SMART-LLM 实现 TCR = 1.0,但由于顺序执行与并行执行的差异,SR 较低,影响 RU。
- 在复合与复杂任务中,成功率为 70%,存在一些排序与团队分配挑战。
- GPT-4 通常优于 GPT-3.5,特别是在需要推理和多样化子技能的复杂任务上。
- 移除注释、摘要或联盟形成通常会降低性能,凸显推理增强提示和结构化提示的价值。
- 实机器人实验表明,该方法能够为仿真中未见的覆盖/巡逻任务分配合适的机器人团队。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。