[论文解读] SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2 是一个 1.7B 参数的语言模型,通过多阶段、数据中心化方法在 ~11T tokens 上训练,使用新的数据集(FineMath、Stack-Edu、SmolTalk);在同等规模的语言模型中达到最新性能,并随同数据发布。
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
研究动机与目标
- 推动开发高效的小型语言模型,以在保持知识、推理、代码和数学能力的同时降低计算成本。
- 研究如何通过谨慎的数据整理和分阶段训练最大化小型语言模型的性能。
- 评估专用数据集(数学、代码、指令遵循)对领域特定与通用能力的影响。
- 提供可复现的训练流程和已发布的数据集,以促进未来在小型语言模型方面的研究。
提出的方法
- 在 ~11T tokens 上使用基于 LLama2 的 1.7B 参数 Transformer,采用多阶段训练计划。
- 系统性评估英文网络数据消融,以指导数据集混合并引入在线再平衡。
- 创建并整合新的专业数据集 FineMath、Stack-Edu 和 SmolTalk,以弥补在数学、代码和指令遵循方面的空白。
- 在后期阶段进行分阶段退火和高质量领域(数学、代码)数据集的上采样,以最大化能力。
- 通过检查点和 RoPE 缩放将上下文长度扩展到 8k token,以支持长上下文任务。
- 在后训练阶段进行指令微调(SmolTalk)和偏好学习(DPO),以生成遵循指令的变体。
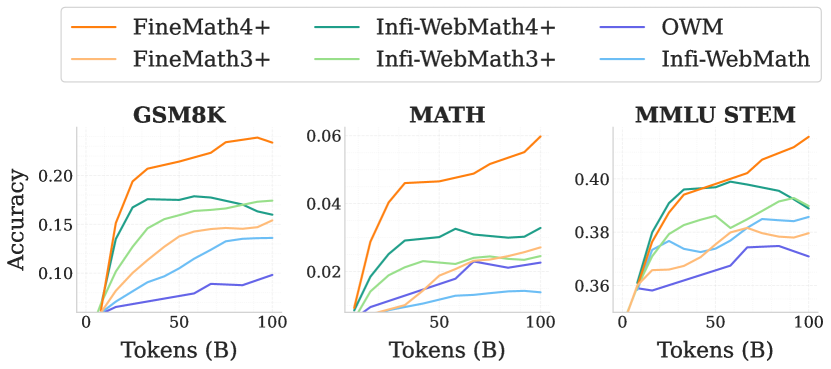
实验结果
研究问题
- RQ1不同数据集构成和阶段性训练如何影响小型语言模型在各基准上的表现?
- RQ2专用数据(数学、代码、指令遵循)是否提升小型语言模型的推理和领域特定能力?
- RQ3数据上采样与后期高质量数据集引入对整体性能有何影响?
- RQ4以数据中心化方法训练的 1.7B 模型是否能达到同等规模语言模型的最新性能?
主要发现
- SmolLM2(1.7B)在1–2B规模范围的若干基准测试中超过 Qwen2.5-1.5B 与 Llama3.2-1B。
- 最终基础版 SmolLM2 展现出很强的泛化能力,与同侪模型相比在 MMLU-Pro、TriviaQA、Natural Questions、GSM8K、MATH 和 HumanEval 上取得显著提升。
- 将上下文长度从 2k 延伸到 8k token 后,性能仍然稳健(未观测到降级)。
- 分阶段的数据混合,在后期阶段加强数学和代码领域,带来数学和编码能力的大幅提升。
- SmolLM2 的指令微调变体(SmolTalk)以及通过直接偏好优化(DPO)进行的对齐进一步提升了指令遵循性能。
- 该研究发布了 SmolLM2 以及所有准备好的数据集(FineMath、Stack-Edu、SmolTalk),以支持未来研究。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。