[论文解读] SnapKV: LLM Knows What You are Looking for Before Generation
SnapKV 是一种无微调的 KV 缓存压缩方法,它从观测窗口中识别并聚类每个头的重要注意力特征,从而在长上下文的 LLM 任务上实现更快的解码和更低的内存使用,且精度相当。
Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an 'observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to the baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to the baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
研究动机与目标
- 研究在生成过程中对提示令牌的注意力是否遵循一致的模式。
- 开发一种 KV 缓存压缩方法,在不牺牲性能的前提下减少提示 KV 的大小。
- 证明逐头特征聚类在保持关键信息的同时能够实现高效的长上下文处理。
- 在多种 LLM 和长上下文基准测试上评估 SnapKV,以确立速度和内存方面的收益。
提出的方法
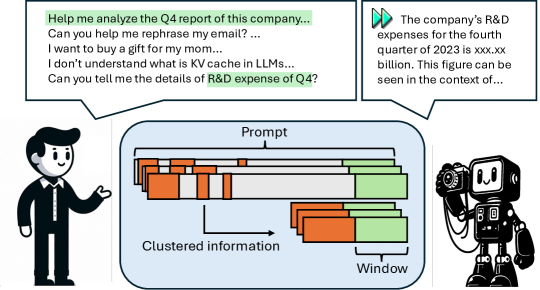
- 分析提示到前缀的注意力,以使用观测窗口识别一致的关键 KV 位置。
- 对注意力权重进行投票和聚合,以在每个头中选择前 K 个重要位置(在汇聚权重上进行 Top-k)。
- 应用一维池化(kernel_size)对邻近的关键位置进行聚类,以实现更细粒度的压缩。
- 将选定的特征与观测窗口拼接后再存储修订后的 KV 缓存以供生成。
- 提供一个实用、最小代码实现的 SnapKV,与常用框架集成。
- 在长上下文数据集和模型上评估准确性与效率,并测试与并行解码的兼容性。
实验结果
研究问题
- RQ1在不同生成上下文中,对提示令牌的注意力分配是否存在一致的模式?
- RQ2提示长度、指令位置和任务类型如何影响所识别出的重要 KV 特征?
- RQ3情境感知的 KV 压缩是否能够在显著减少 KV 缓存大小的同时保持生成质量?
主要发现
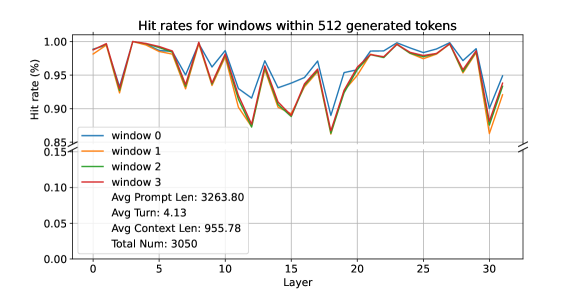
- 在生成过程中,对某些提示键的注意力分配在跨上下文时仍然非常一致。
- 指令位置(在上下文之前与之后)会产生较高的命中率,而不同的指令会改变被视为重要的前缀键。
- 基于池化的聚类在 KV 压缩中提高了检索精度,相较于简单的 top-K 选择。
- 与基线相比,SnapKV 在 16K 令牌输入下实现了 3.6x 更快的解码和 8.2x 的内存效率提升。
- 在单个 A100-80GB GPU 上,SnapKV 最多可处理 380K 上下文令牌,在 Needle-in-a-Haystack 测试中精度下降微乎其微。
- 在 LongBench 上,将提示 KV 缓存压缩到 1024/2048/4096 令牌时,性能损失可忽略不计,1024 时平均压缩 92%,4096 时为 68%。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。