[论文解读] SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes
SOD-YOLOv8 通过基于 Efficient GFPN 的高效多尺度融合、C2f-EMA 注意力模块、额外的高分辨检测层,以及 PIoU 损失来提高交通场景中的小对象检测,且不会显著增加延迟。
Object detection as part of computer vision can be crucial for traffic management, emergency response, autonomous vehicles, and smart cities. Despite significant advances in object detection, detecting small objects in images captured by distant cameras remains challenging due to their size, distance from the camera, varied shapes, and cluttered backgrounds. To address these challenges, we propose Small Object Detection YOLOv8 (SOD-YOLOv8), a novel model specifically designed for scenarios involving numerous small objects. Inspired by Efficient Generalized Feature Pyramid Networks (GFPN), we enhance multi-path fusion within YOLOv8 to integrate features across different levels, preserving details from shallower layers and improving small object detection accuracy. Also, A fourth detection layer is added to leverage high-resolution spatial information effectively. The Efficient Multi-Scale Attention Module (EMA) in the C2f-EMA module enhances feature extraction by redistributing weights and prioritizing relevant features. We introduce Powerful-IoU (PIoU) as a replacement for CIoU, focusing on moderate-quality anchor boxes and adding a penalty based on differences between predicted and ground truth bounding box corners. This approach simplifies calculations, speeds up convergence, and enhances detection accuracy. SOD-YOLOv8 significantly improves small object detection, surpassing widely used models in various metrics, without substantially increasing computational cost or latency compared to YOLOv8s. Specifically, it increases recall from 40.1\% to 43.9\%, precision from 51.2\% to 53.9\%, $ ext{mAP}_{0.5}$ from 40.6\% to 45.1\%, and $ ext{mAP}_{0.5:0.95}$ from 24\% to 26.6\%. In dynamic real-world traffic scenes, SOD-YOLOv8 demonstrated notable improvements in diverse conditions, proving its reliability and effectiveness in detecting small objects even in challenging environments.
研究动机与目标
- 解决交通场景和 UAV 图像中小目标检测的挑战。
- 改进特征融合以保留小对象的浅层空间细节。
- 引入基于注意力的 C2f-EMA 模块,通过通道重新加权特征。
- 引入 Powerful-IoU(PIoU)以改善边界框回归和收敛性。
- 在真实交通图像上对比 YOLOv8 及其他基线评估性能。
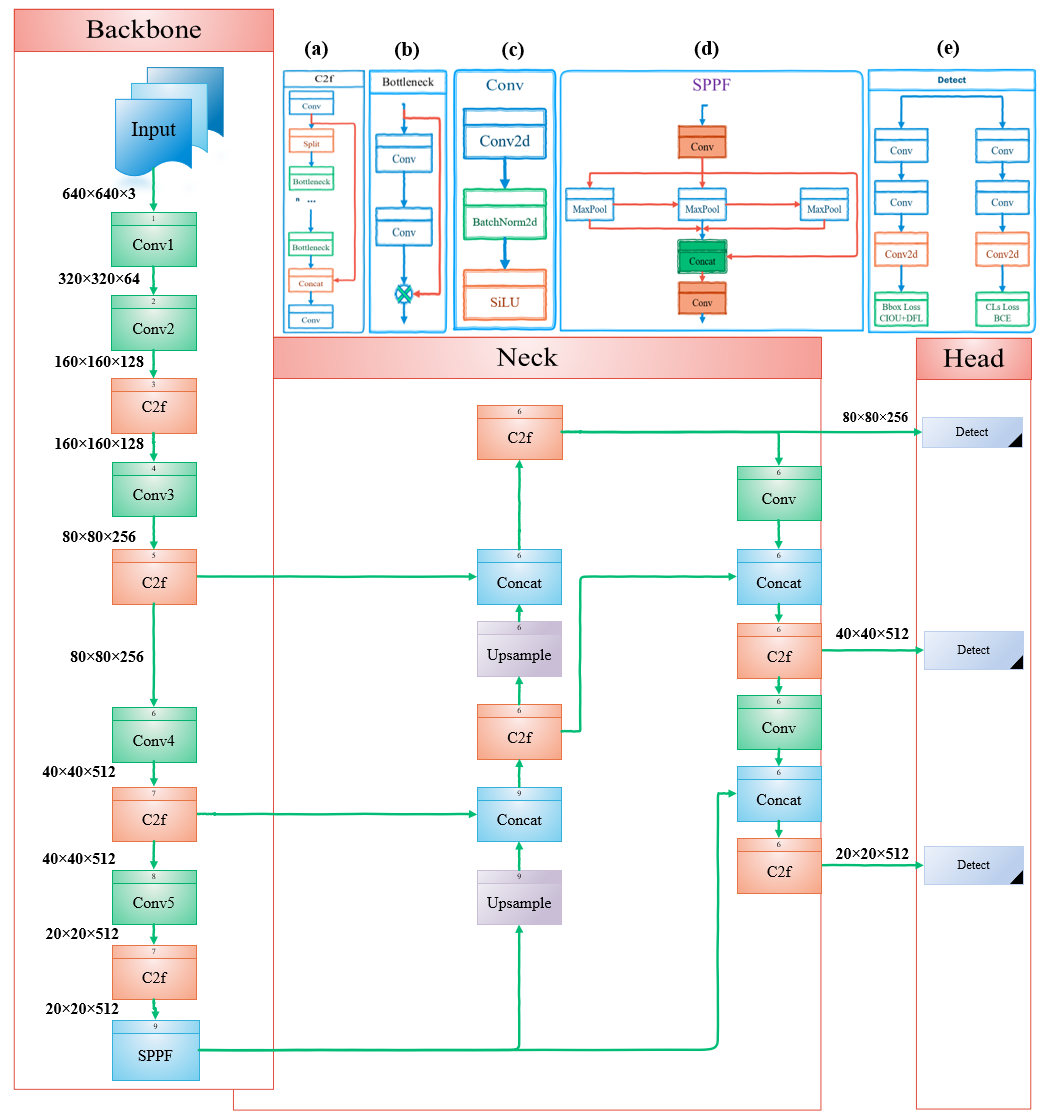
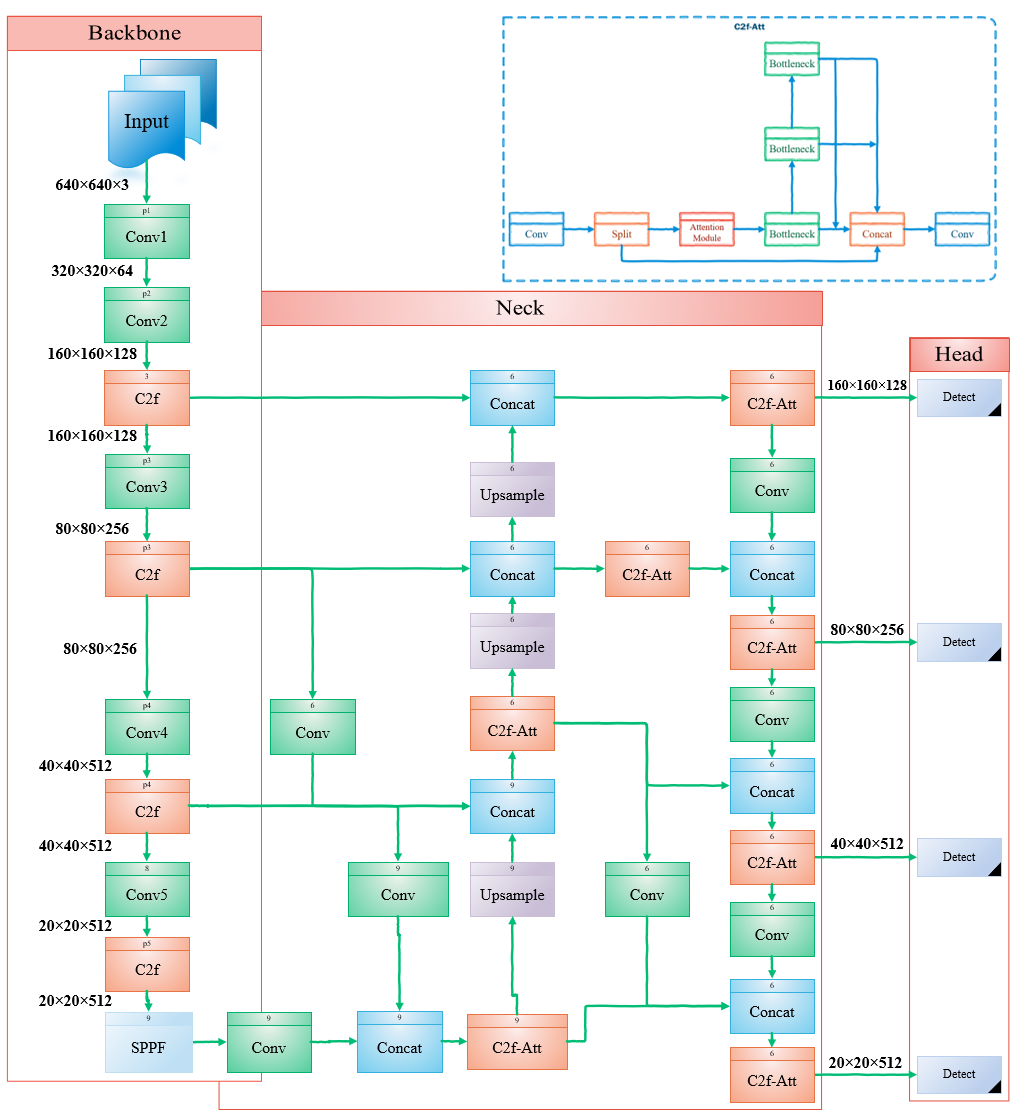
提出的方法
- 用受 Efficient-RepGFPN 启发的增强 GFPN 替换 PAFPN,以通过跳层和 queen 融合连接改进多尺度特征融合。
- 通过整合 P2 特征增加第四检测层,以保留小对象的高分辨率空间细节。
- 引入 C2f-EMA,替代 C2f,通过高效多尺度注意力重新分配通道权重,以获得更好的小对象表示。
- 在边界框回归损失中用 PIoU 替代 CIoU,以加速收敛并改善定位稳定性。
- 提供基于 EMA 的 C2f-EMA 机制的详细描述,包括 1x1 与 3x3 分支以及 2D 空间注意力处理。
- 通过可视化分析和真实世界交通图像证明该方法在不显著增加延迟的前提下提升小对象检测。
实验结果
研究问题
- RQ1如何重新设计多尺度特征融合,以保留对于 YOLOv8 的小对象至关重要的浅层空间细节?
- RQ2C2f-EMA 注意力模块是否提升了小对象检测性能和在 YOLOv8 颈部的特征表示?
- RQ3在中等质量的锚框上,PIoU 是否比 CIoU 提供更快的收敛和更好的边界框回归?
- RQ4增加第四检测层以利用高分辨率特征对小对象检测精度和延迟的影响是什么?
- RQ5在真实世界动态交通场景中,SOD-YOLOv8 相较于基线 YOLOv8s 及其他小对象检测器的表现如何?
主要发现
- 召回率从 40.1% 提升到 43.9%。
- 精确度从 51.2% 提升到 53.9%。
- mAP@0.5 从 40.6% 提升到 45.1%。
- mAP@0.5:0.95 从 24% 提升到 26.6%。
- 与 YOLOv8s 相比,SOD-YOLOv8 在延迟和计算成本方面仅有适度的变化就实现了这些提升。
- 可视化分析和真实世界交通图像在多变条件下验证了更好的小对象检测。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。