[论文解读] SOEN-101: Code Generation by Emulating Software Process Models Using Large Language Model Agents
简述:LCG 使用多代理大模型来模拟 Waterfall、TDD 和 Scrum 流程进行代码生成;基于 Scrum 的 LCG 在 Pass@1 增益方面表现最佳,并在不同模型变体下结果更稳定。
Software process models are essential to facilitate collaboration and communication among software teams to solve complex development tasks. Inspired by these software engineering practices, we present FlowGen - a code generation framework that emulates software process models based on multiple Large Language Model (LLM) agents. We emulate three process models, FlowGenWaterfall, FlowGenTDD, and FlowGenScrum, by assigning LLM agents to embody roles (i.e., requirement engineer, architect, developer, tester, and scrum master) that correspond to everyday development activities and organize their communication patterns. The agents work collaboratively using chain-of-thought and prompt composition with continuous self-refinement to improve the code quality. We use GPT3.5 as our underlying LLM and several baselines (RawGPT, CodeT, Reflexion) to evaluate code generation on four benchmarks: HumanEval, HumanEval-ET, MBPP, and MBPP-ET. Our findings show that FlowGenScrum excels compared to other process models, achieving a Pass@1 of 75.2, 65.5, 82.5, and 56.7 in HumanEval, HumanEval-ET, MBPP, and MBPP-ET, respectively (an average of 15% improvement over RawGPT). Compared with other state-of-the-art techniques, FlowGenScrum achieves a higher Pass@1 in MBPP compared to CodeT, with both outperforming Reflexion. Notably, integrating CodeT into FlowGenScrum resulted in statistically significant improvements, achieving the highest Pass@1 scores. Our analysis also reveals that the development activities impacted code smell and exception handling differently, with design and code review adding more exception handling and reducing code smells. Finally, FlowGen models maintain stable Pass@1 scores across GPT3.5 versions and temperature values, highlighting the effectiveness of software process models in enhancing the quality and stability of LLM-generated code.
研究动机与目标
- 以多代理过程来建模软件开发,以提升代码质量和可靠性。
- 提出 LCG,一种基于代理的框架,用于为代码生成模拟 Waterfall、TDD 与 Scrum。
- 研究开发活动和过程模型如何影响可靠性、代码异味等代码质量属性。
- 评估在不同的 LLM 模型版本和温度设置下的稳定性。
提出的方法
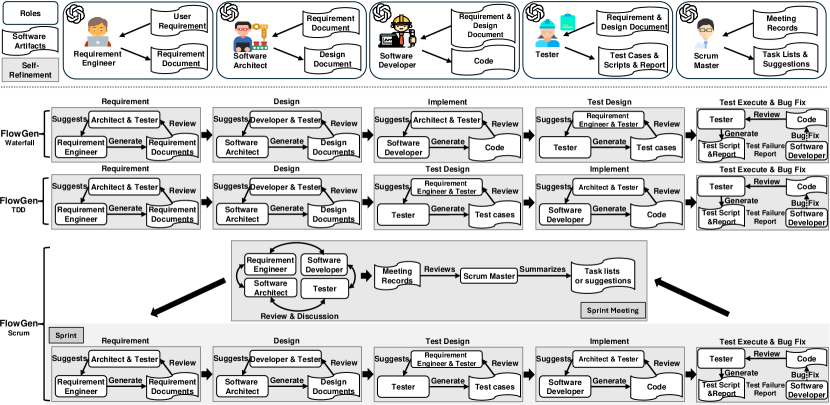
- 将开发角色(需求工程师、架构师、开发者、测试员;Scrum 中的 Scrum Master)定义为 LLM 代理。
- 实现三种交互模式,分别对应 Waterfall(有序)、TDD(有序,先测试后实现)和 Scrum(无序,类似冲刺的会议)。
- 应用链式推理、提示组合和自我完善以迭代改进产物。
- 使用零-shot 提示在四个基准上评估(HumanEval、HumanEval-ET、MBPP、MBPP-ET),以 Pass@1 作为主要指标。
- 在相同条件下与 GPT-3.5 基线(GPT)进行比较,并分析代码异味与异常处理。
实验结果
研究问题
- RQ1将 Waterfall、TDD、Scrum 等不同软件过程模型的模拟,与 GPT 基线相比,对代码生成准确性(Pass@1)的影响?
- RQ2哪些开发活动会影响可靠性、代码异味等代码质量属性?
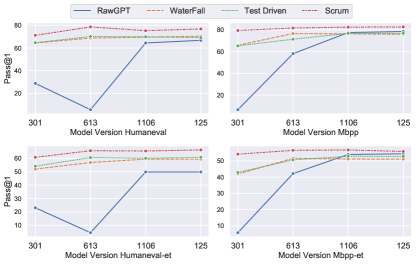
- RQ3LCG 结果在不同的 GPT-3.5 模型版本和温度设置下有多稳定?
主要发现
| 模型 | HumanEval | HumanEval-ET | MBPP | MBPP-ET |
|---|---|---|---|---|
| GPT | 64.4 ± 3.7 | 49.8 ± 3.0 | 77.5 ± 0.8 | 53.9 ± 0.7 |
| LCG_Waterfall | 69.5 ± 2.3 | 59.4 ± 2.5 | 76.3 ± 0.9 | 51.1 ± 1.7 |
| LCG_TDD | 69.8 ± 2.2 | 60.0 ± 2.1 | 76.8 ± 0.9 | 52.8 ± 0.7 |
| LCG_Scrum | 75.2 ± 1.1 | 65.5 ± 1.9 | 82.5 ± 0.6 | 56.7 ± 1.4 |
- LCG_Scrum 在所有基准上的 Pass@1 最高:75.2(HumanEval),65.5(HumanEval-ET),82.5(MBPP),56.7(MBPP-ET)。
- LCG 变体通常优于 GPT 基线,Pass@1 提升幅度为 5.2% 到 31.5%。
- LCG_Scrum 在基准间的平均标准差为 1.3%,显示出最稳定的结果。
- 移除测试会大幅降低 Pass@1(下降 17.0% 到 56.1%),并增加代码异味。
- 设计和代码评审减少重构和警告异味,改善异常处理。
- GPT 模型版本差异显著影响质量,而 LCG 在版本和温度之间提供稳定性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。