[论文解读] Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
Sophia 引入一种轻量级二阶优化器,使用对角 Hessian 预条件器并进行逐坐标裁剪,在GPT类语言模型预训练中比 AdamW 提供大约 2x 的加速,且开销不大。
Given the massive cost of language model pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT models of sizes ranging from 125M to 1.5B, Sophia achieves a 2x speed-up compared to Adam in the number of steps, total compute, and wall-clock time, achieving the same perplexity with 50% fewer steps, less total compute, and reduced wall-clock time. Theoretically, we show that Sophia, in a much simplified setting, adapts to the heterogeneous curvatures in different parameter dimensions, and thus has a run-time bound that does not depend on the condition number of the loss.
研究动机与目标
- 动机:解决语言模型预训练的高成本,以及超越 Adam 和简单的一阶方法的更快优化器的需求。
- 开发一种轻量级的二阶优化器,在利用曲率信息的同时降低每步开销。
- 在不牺牲模型性能的前提下,实现训练步数、总计算量和实际用时的显著降低。
- 提供理论与实证证据,表明对角 Hessian 预条件器能够适应参数之间的异构曲率。
提出的方法
- 提出 Sophia,它使用梯度的移动平均除以对角 Hessian 估计的移动平均作为更新方向。
- 每 k 步估计一次对角 Hessian(k=10),有两种选项:Hutchinson 的无偏估计器(Hessian-向量积)和 Gauss-Newton-Bartlett (GNB) 估计器(Gauss-Newton/Hessian 的对角线)。
- 应用逐坐标裁剪以控制最坏情况的更新幅度,并确保在非凸景观中的鲁棒性。
- 更新规则将梯度 EMA、对角 Hessian 预条件器和裁剪结合起来:theta_{t+1} = theta_t - eta_t * clip(m_t / max{gamma * h_t, epsilon}, 1)。
- 为 PSD 预条件器维持对角 Hessian 正值条目,以确保下降方向。
- 展示在现有流水线中以最小开销集成的可行性,并兼容 PyTorch/JAX。
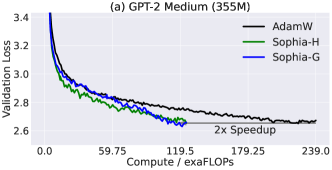
实验结果
研究问题
- RQ1基于对角 Hessian 的轻量级预条件器结合裁剪,是否能相对于 AdamW 加速语言模型预训练?
- RQ2两种估计器(Hutchinson 和 Gauss-Newton-Bartlett)是否在大型语言模型中提供可接受开销的可靠对角 Hessian 估计?
- RQ3在从 125M 到 6.6B 参数的模型尺度下,Sophia 在达到相同验证损失所需的步数与总计算量方面的表现如何?
- RQ4逐坐标裁剪机制是否提升非凸LLM景观中的稳定性和收敛性?
- RQ5在简化设置中,哪些理论洞见可以解释 Sophia 对异质曲率的适应以及其运行时间对条件数的独立性?
主要发现
- 在 GPT-2 和 GPT NeoX 的预训练中,Sophia 在步数、总计算量和实际用时方面相比 AdamW 约有 2 倍的加速,跨越不同模型规模。
- Sophia 以大约 50% 的步数达到相同的验证预训练损失,且总计算量和实际用时也减少约 50%。
- 从 125M 到 1.5B+ 参数的模型尺度,Sophia 与 AdamW 之间的性能差距扩大,越大模型收益越多。
- 两种对角 Hessian 估计器(Hutchinson 和 Gauss-Newton-Bartlett)引入约 5% 的每步开销,并实现可扩展的预条件化。
- 裁剪机制可防止负曲率和霍森变化过快,提升鲁棒性并防止牛顿式失败。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。