[论文解读] Sources of Hallucination by Large Language Models on Inference Tasks
本论文识别出两种在预训练中诱导的偏差,这些偏差在自然语言推理中导致 LLMs 产生幻觉:对已证实假设的记忆以及基于语料库频率的蕴涵。它展示这些偏差在 LLaMA、GPT-3.5、和 PaLM 上会造成假阳性并降低对不符合样本的表现。
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two biases originating from pretraining which predict much of their behavior, and show that these are major sources of hallucination in generative LLMs. First, memorization at the level of sentences: we show that, regardless of the premise, models falsely label NLI test samples as entailing when the hypothesis is attested in training data, and that entities are used as ``indices'' to access the memorized data. Second, statistical patterns of usage learned at the level of corpora: we further show a similar effect when the premise predicate is less frequent than that of the hypothesis in the training data, a bias following from previous studies. We demonstrate that LLMs perform significantly worse on NLI test samples which do not conform to these biases than those which do, and we offer these as valuable controls for future LLM evaluation.
研究动机与目标
- 识别导致幻觉的 LLM 自然语言推理中的偏差。
- 将基于 memorization 的偏差和基于语料统计的偏差区分为预训练产物。
- 评估这些偏差如何影响对已证实假设和基于频率的蕴涵的预测。
提出的方法
- 在 LLaMA-65B、GPT-3.5 和 PaLM-540B 上进行有控的数据集转换以开展行为性 NLI 实验。
- 将 Attestation Bias (Λ) 定义为对训练数据中假设证实的依赖,并通过证实提示进行测量。
- 将 Relative Frequency Bias (Φ) 定义为训练语料中前提与假设的频率差异,使用 Google N-grams 作为代理。
- 使用 Levy/Holt 与 RTE-1 风格的提示,提供三选一的 NLI 选项以及最少的少量示例来探查记忆和偏差效应。
- 应用数据集转换 (I_RandPrem, I_GenArg, I_RandArg, I_RandArg↑/↓) 将记忆效应与表面信号分离。
- 通过 recall/precision 指标和 AUC_norm,在 bias-consistent 与 bias-adversarial 子集上评估影响。
实验结果
研究问题
- RQ1在解决 NLI 任务时,LLMs 是否依赖对训练数据的命题记忆?
- RQ2命名实体是否作为记忆索引在推理中的召回中起关键作用?
- RQ3语料频率偏差是否在不依赖语义内容的前提下驱动蕴涵判断?
- RQ4这些偏差如何影响模型在符合偏差与与之矛盾的样本上的表现?
主要发现
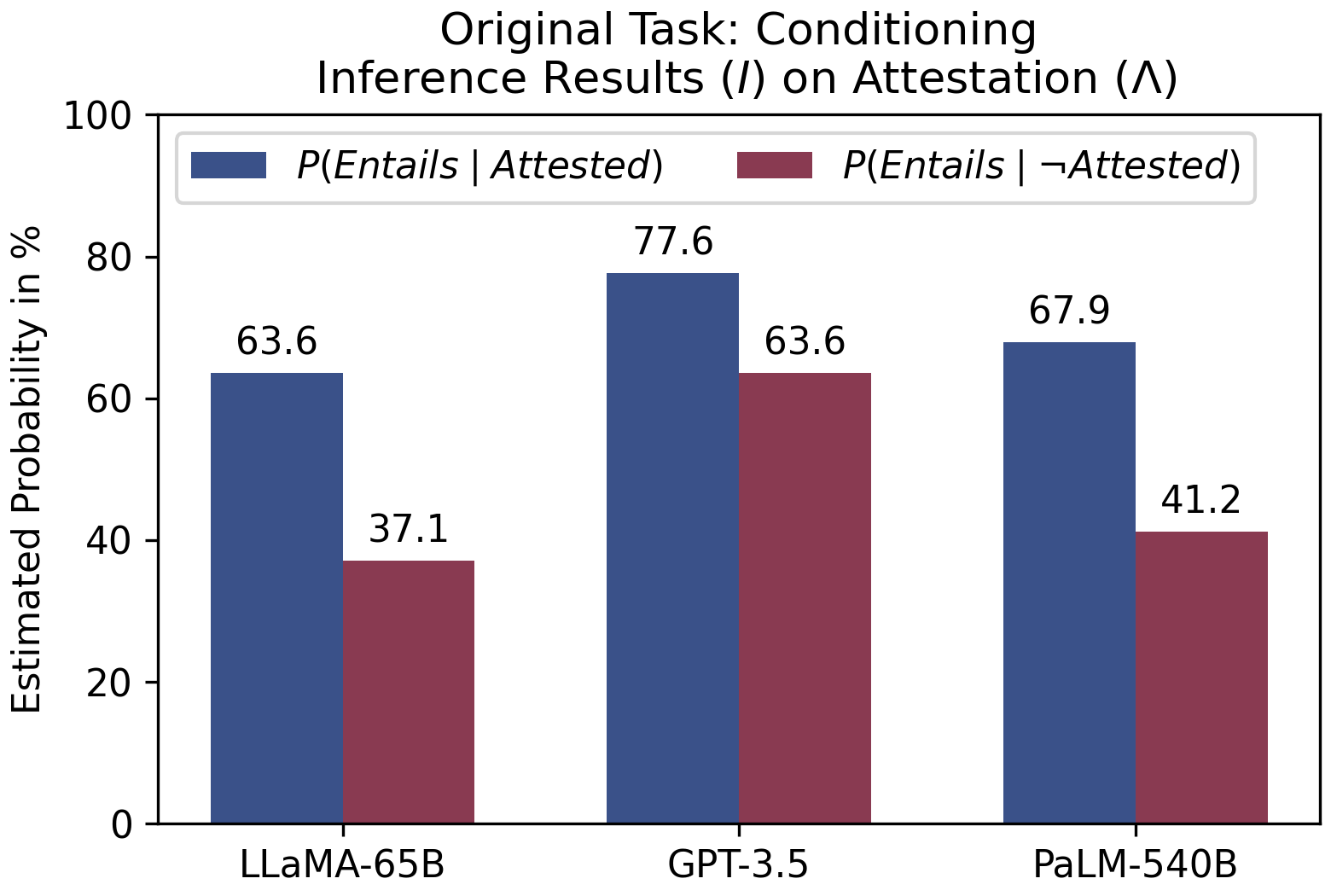
- 当假设在训练数据中被证实时,LLMs 展现出更高的 Entail 预测,表明存在 Attestation Bias (Λ)。
- 用通用或随机实体替换实体会降低召回,表明命名实体充当召回的记忆索引。
- 模型表现出 Relative Frequency Bias (Φ),当前提在训练数据中的频率低于假设时,蕴涵更可能。
- 在 LLaMA、GPT-3.5 与 PaLM 中,基于记忆和频率的偏差导致大量的假阳性并降低对抗样本的表现。
- 证实性与频率偏差在模型家族间持续存在,并且与预训练目标相关,而非微调或 RLHF。
- 在使用 bias-consistent 与 bias-adversarial 子集进行评估时,传统的 NLI 分数可能会误导关于真实推理能力的判断。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。