[论文解读] Sparks of GPTs in Edge Intelligence for Metaverse: Caching and Inference for Mobile AIGC Services
论文提出一个在移动边缘服务器对预训练基础模型进行联合模型缓存与推理的框架,引入 Age of Context 概念,并显示 Least Context 算法能够降低系统成本并提升边缘执行。
Aiming at achieving artificial general intelligence (AGI) for Metaverse, pretrained foundation models (PFMs), e.g., generative pretrained transformers (GPTs), can effectively provide various AI services, such as autonomous driving, digital twins, and AI-generated content (AIGC) for extended reality. With the advantages of low latency and privacy-preserving, serving PFMs of mobile AI services in edge intelligence is a viable solution for caching and executing PFMs on edge servers with limited computing resources and GPU memory. However, PFMs typically consist of billions of parameters that are computation and memory-intensive for edge servers during loading and execution. In this article, we investigate edge PFM serving problems for mobile AIGC services of Metaverse. First, we introduce the fundamentals of PFMs and discuss their characteristic fine-tuning and inference methods in edge intelligence. Then, we propose a novel framework of joint model caching and inference for managing models and allocating resources to satisfy users' requests efficiently. Furthermore, considering the in-context learning ability of PFMs, we propose a new metric to evaluate the freshness and relevance between examples in demonstrations and executing tasks, namely the Age of Context (AoC). Finally, we propose a least context algorithm for managing cached models at edge servers by balancing the tradeoff among latency, energy consumption, and accuracy.
研究动机与目标
- Motivate AGI-enabled Metaverse services via PFMs like GPTs at the edge to enable low-latency, privacy-preserving AIGC.
- Develop a joint model caching and inference framework that optimizes resource allocation across mobile edge and cloud layers.
- Introduce Age of Context (AoC) to measure in-context demo relevance and freshness.
- Propose the Least Context (LC) caching algorithm to manage cached PFMs based on contextual usefulness.
提出的方法
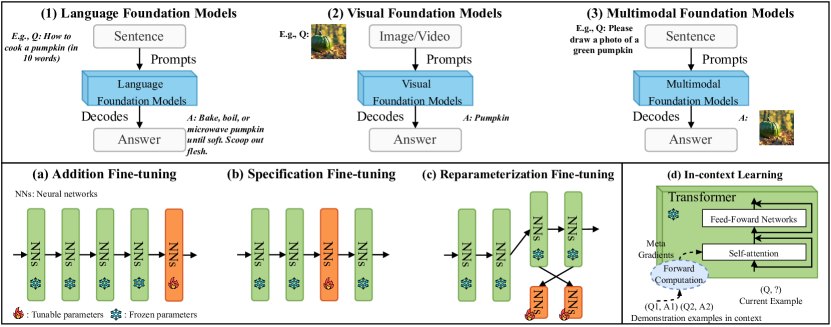
- Classify PFMs into LFMs, VFMs, and MFMs and summarize their fine-tuning and inference approaches in edge settings.
- Define a joint model caching and inference framework with edge-cloud collaboration and dynamic cache management.
- Introduce AoC as a metric to capture freshness/relevance of context examples during in-context learning.
- Propose the LC algorithm that evicts the cached model with the fewest context examples when GPU memory is needed.
- Provide a comparative evaluation against Random, Cloud, FIFO, and LFU baselines across a multi-metric cost model.
- Present an illustrative use-case and analyze performance via a results table (Table II).
实验结果
研究问题
- RQ1How can mobile edge-cloud systems optimally cache and execute PFMs to satisfy latency and accuracy objectives?
- RQ2What is the impact of in-context learning context (AoC) on PFM inference performance in edge environments?
- RQ3Does the Least Context caching strategy outperform traditional caching policies in terms of system cost and edge execution ratio?
主要发现
| 指标 | 随机 | 云端 | 先进先出 | 最近最少使用 | LC |
|---|---|---|---|---|---|
| 系统成本 | 25.67 | 7.29 | 27.51 | 5.93 | 4.88 |
| 切换成本 | 18.72 | 0 | 23.28 | 0.37 | 0.32 |
| 总准确性成本 | 0.13 | 0 | 0.52 | 0.36 | 0.44 |
| 平均准确性成本 | 0.0151 | 0 | 0.0085 | 0.0083 | 0.0076 |
| 推理延迟 | 0.12 | 0 | 1.30 | 1.32 | 1.26 |
| 卸载延迟 | 0.04 | 0 | 0.35 | 0.24 | 0.31 |
| 云端成本 | 6.63 | 7.29 | 2.05 | 3.63 | 2.52 |
| 边缘执行比例 | 9.8% | 0% | 70.7% | 49.4% | 65.0% |
- The LC algorithm reduces total system cost compared with baselines.
- LC achieves a higher edge execution ratio than some baselines, indicating more inference at the edge.
- AoC-based context management enables better utilization of in-context learning to improve accuracy.
- In experiments, LC shows lower average accuracy cost and competitive inference/latency metrics versus alternatives.
- The framework demonstrates that joint edge-cloud collaboration with dynamic, context-aware caching is beneficial for mobile AIGC services.
![Figure 2: An illustration of the performance of zero-, one-, and few-shot accuracy under different model caching settings [ 3 ] .](https://ar5iv.labs.arxiv.org/html/2304.08782/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。