[论文解读] Sparse Autoencoders Find Highly Interpretable Features in Language Models
本文使用稀疏自编码器从语言模型激活中学习特征字典,生成更具可解释性、单义性方向,能够对模型输出产生因果影响并减少叠加现象。
One of the roadblocks to a better understanding of neural networks' internals is extit{polysemanticity}, where neurons appear to activate in multiple, semantically distinct contexts. Polysemanticity prevents us from identifying concise, human-understandable explanations for what neural networks are doing internally. One hypothesised cause of polysemanticity is extit{superposition}, where neural networks represent more features than they have neurons by assigning features to an overcomplete set of directions in activation space, rather than to individual neurons. Here, we attempt to identify those directions, using sparse autoencoders to reconstruct the internal activations of a language model. These autoencoders learn sets of sparsely activating features that are more interpretable and monosemantic than directions identified by alternative approaches, where interpretability is measured by automated methods. Moreover, we show that with our learned set of features, we can pinpoint the features that are causally responsible for counterfactual behaviour on the indirect object identification task \citep{wang2022interpretability} to a finer degree than previous decompositions. This work indicates that it is possible to resolve superposition in language models using a scalable, unsupervised method. Our method may serve as a foundation for future mechanistic interpretability work, which we hope will enable greater model transparency and steerability.
研究动机与目标
- 通过解决语言模型中的多义性和叠加现象来推动机制可解释性。
- 开发一种无监督方法,从内部激活中提取可解释的特征方向。
- 证明学习到的字典特征在自解释性上高于基线。
- 展示字典特征对特定任务的模型行为具有因果相关性。
提出的方法
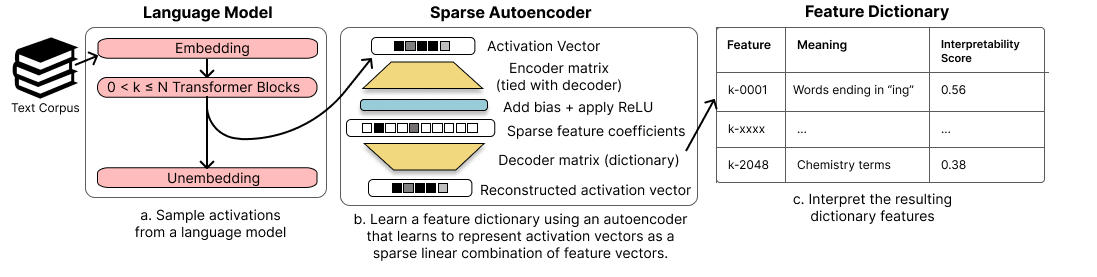
- 对隐藏激活施加稀疏性惩罚来训练稀疏自编码器,从语言模型激活(残差流、MLP 子层或注意力头子层)中学习特征字典。
- 使用成对的编码器/解码器权重以及字典特征的逐行归一化。
- 使用 L1 稀疏项来优化重建损失以恢复真实特征(L2 重建损失 + alpha * ||c||1)。
- 用来自语言模型对字典特征激活的解释所得到的自解释性分数来评估可解释性。
- 与基线(默认基底、随机方向、PCA、ICA)在学习特征的可解释性方面进行比较。
- 应用激活打补丁和自动化电路发现(ACDC)以定位字典特征对间接宾语识别(IOI)任务的因果影响。
实验结果
研究问题
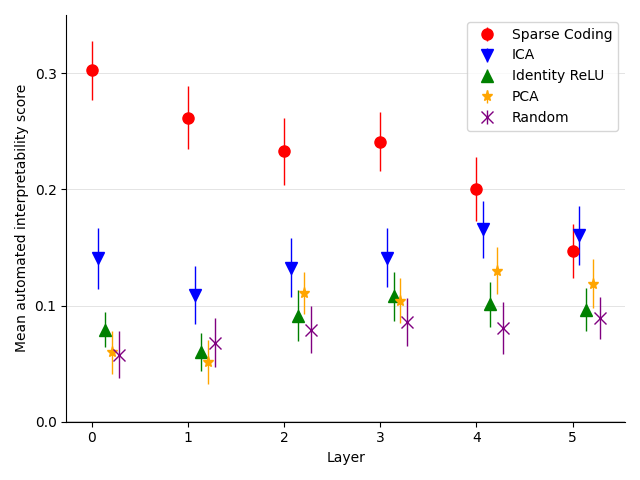
- RQ1与其他分解相比,稀疏字典特征是否降低多义性并提高可解释性?
- RQ2稀疏字典特征是否可用于在目标任务上精确定位并对模型输出产生因果影响?
- RQ3在可解释性和对输出的因果影响方面,字典特征相对于 PCA/ICA/随机基线的表现如何?
- RQ4稀疏程度和字典大小在学习到的特征质量与效用中起什么作用?
主要发现
- 字典特征在平均上比神经元及若干基线更具可解释性,衡量标准为自解释性分数。
- 稀疏字典在 IOI 上以更少的打补丁和更小的修改更高效地定位因果特征,优于基于 PCA 的分解。
- 出现单义性字典特征,对窄小的语言令牌(如撇号、句点)有激活,并对下一个词的对数概率有可预测的影响。
- 使用稀疏字典的激活打补丁在修改幅度与修改彻底性之间实现了比非稀疏字典更好的帕累托前沿。
- 案例研究显示与可解释的语言现象相符的特征,并揭示跨层的上游/下游因果关系。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。