[论文解读] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
SparseGPT 提出了一种一次性修剪方法,可以将巨型 GPT-family 模型(例如 OPT-175B、BLOOM-176B)稀疏化到 50–60% 的非结构化稀疏度且精度损失可以忽略,且无需重新训练。
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy. This is achieved via a new pruning method called SparseGPT, specifically designed to work efficiently and accurately on massive GPT-family models. We can execute SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, in under 4.5 hours, and can reach 60% unstructured sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time. SparseGPT generalizes to semi-structured (2:4 and 4:8) patterns, and is compatible with weight quantization approaches. The code is available at: https://github.com/IST-DASLab/sparsegpt.
研究动机与目标
- 有必要将大规模 GPT 级别模型进行压缩,以降低部署成本和推理延迟,且无需重新训练。
- 引入 SparseGPT,一种面向 10–100+ 亿参数变换器的可扩展一次性修剪方法。
- 展示更大规模的模型更具可压缩性,并且可以在精度损失很小的情况下实现高稀疏性修剪。
- 证明 SparseGPT 与半结构化稀疏模式以及权重量化的兼容性,从而实现联合稀疏化与量化。
提出的方法
- 把修剪问题简化为大型稀疏回归实例,由一种新的近似稀疏回归求解器解决。
- 开发一种快速重建技术,使用自适应的逐层 Hessian 基更新,在修剪后保持输入与输出关系。
- 通过一系列逐列更新重用逆 Hessian,同步跨行的 Hessian,使总体复杂度达到 O(d_hidden^3) 每层的。
- 采用自适应掩码策略,将列分块以实现跨层非均匀稀疏分布,并以基于 OBS 的误差估计为引导。
- 通过调整块处理扩展到半结构化稀疏性(2:4、4:8),在块内强制稀疏约束。
- 通过将权重量化整合到修剪阶段,并在更新中传播其影响,实现在单次传递中实现联合稀疏化与量化。
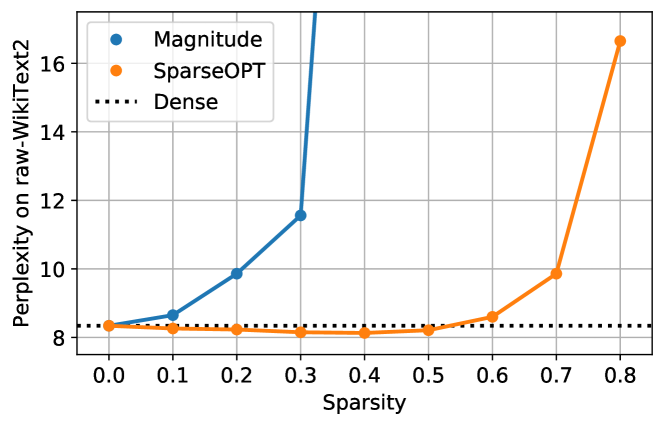
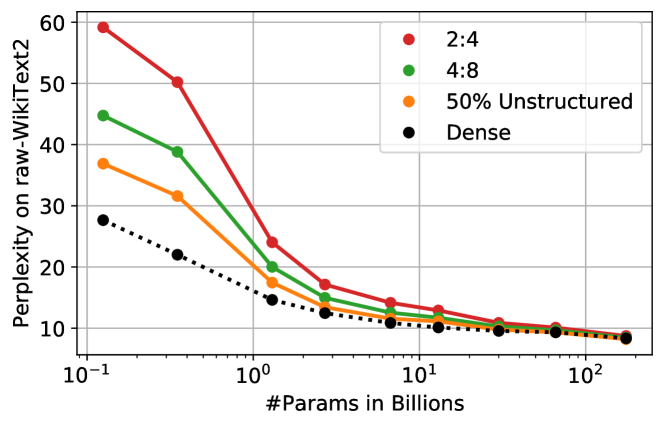
实验结果
研究问题
- RQ1一次性修剪是否能在不重新训练的情况下对 GPT 规模模型实现显著稀疏?
- RQ2在万亿级参数的变换器家族中,未结构化和半结构化稀疏在最小精度损失下能压缩到何种程度?
- RQ3修剪性能是否与模型规模相关,即更大模型是否更易压缩?
- RQ4是否能在单次传递中将稀疏化与权重量化有效结合,而不降低精度?
- RQ5对于大型 LLM,哪些实用的掩码策略最能将稀疏性非均匀地分布在各层?
主要发现
- SparseGPT 在 OPT-175B 和 BLOOM-176B 上一次性实现 50–60% 的非结构化稀疏,困惑度降幅极小。
- 更大的模型显示出更强的可压缩性,在固定稀疏度下的精度损失小于较小模型。
- 2:4 与 4:8 半结构化稀疏在非常大模型上可以实现,且相比未结构化稀疏带来较小的额外精度损失。
- 在极大模型上,联合稀疏化与 4 位权重量化可以在单次传递中完成,困惑度上升可忽略。
- SparseGPT 在单个 A100 GPU 上运行,修剪 OPT-175B 与 BLOOM-176B 在 4.5 小时内完成,展示了实际的可扩展性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。