[论文解读] SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
SPDF 在预训练阶段对权重进行非结构化稀疏化以减少 FLOPs,随后在微调阶段进行密集化以恢复容量并维持下游性能。
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also lead to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity, while retaining the benefits of pre-trained textual representations for downstream tasks.
研究动机与目标
- 在不牺牲下游精度的前提下,推动降低预训练计算成本。
- 提出稀疏预训练与密集微调(SPDF)作为两阶段训练框架。
- 证明在预训练阶段高稀疏度(高达75%)可以在密集微调后保持性能的同时降低 FLOPs。
- 研究稀疏度水平如何与任务难度、数据集规模和模型规模相关。
- 分析预训练和微调模型之间的参数子空间移动。
提出的方法
- 在预训练前,对一个密集的 GPT 风格模型应用统一的静态非结构化稀疏性。
- 在大型文本语料库上对稀疏模型进行预训练,以固定的稀疏掩码最小化带掺遮自回归目标。
- 通过重新激活之前全部零化的权重(初始化为零)并在下游任务上进行密集更新,转入密集微调阶段。
- 在自然语言生成和文本摘要任务上进行评估,以评估下游迁移性。
- 测量 FLOPs 并与密集训练进行比较以量化效率提升。
实验结果
研究问题
- RQ1在预训练阶段高稀疏度(50-75%)是否会在密集微调后保留下游性能?
- RQ2SPDF 的稀疏性如何与数据集规模和任务难度交互?
- RQ3更大模型规模(如 GPT-3 XL)是否能容忍更高稀疏性且对下游影响较小?
- RQ4在不同模型规模和任务下,SPDF 能实现的 FLOP 降低幅度是多少?
- RQ5在 SPDF 下,预训练与微调的参数子空间关系是怎样的?
主要发现
| Model | Pre-Train Sparsity | E2E FLOPs (×10^18) | WebNLG FLOPs (×10^18) | DART FLOPs (×10^18) | Curation Corpus FLOPs (×10^18) |
|---|---|---|---|---|---|
| GPT-2 Small | 0% | 2.48 (1.00x) | 2.48 (1.00x) | 2.45 (1.00x) | 2.44 (1.00x) |
| GPT-2 Small | 50% | 1.84 (1.34x) | 1.82 (1.35x) | 1.84 (1.34x) | 1.81 (1.35x) |
| GPT-2 Small | 75% | 1.52 (1.64x) | 1.49 (1.65x) | 1.52 (1.64x) | 1.48 (1.65x) |
| GPT-3 XL | 0% | 236.62 (1.00x) | 236.62 (1.00x) | 236.33 (1.00x) | 236.32 (1.00x) |
| GPT-3 XL | 50% | 142.40 (1.66x) | 142.10 (1.66x) | 142.01 (1.66x) | 142.40 (1.66x) |
| GPT-3 XL | 75% | 95.29 (2.48x) | 94.98 (2.49x) | 95.29 (2.48x) | 94.90 (2.49x) |
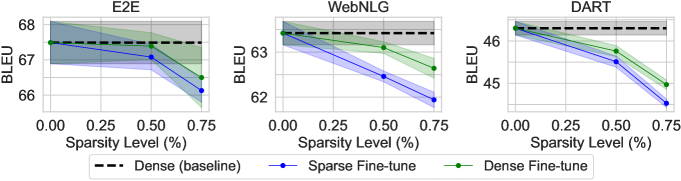
- 在 GPT-2 Small 和 GPT-3 XL 上进行高达 75% 的稀疏预训练,在若干 NLP 任务上仅有有限的 BLEU/困惑度下降,且较大模型对稀疏性具有更强的容忍度。
- 在稀疏预训练后进行密集微调相比仅进行稀疏微调能缓解性能损失。
- SPDF 实现了显著的 FLOP 降低,且随模型规模增大而扩大:在 75% 稀疏预训练时,GPT-2 Small 约实现 1.65x,总 FLOP 降低,GPT-3 XL 约 2.48x 至 2.49x。
- 下游任务难度与稀疏容忍度相关;整理语料库(摘要)对高稀疏性比 E2E、WebNLG 或 DART 更敏感。
- 更大模型在预训练和微调的参数子空间之间的余弦距离更小,表明微调阶段需要的适应较少。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。