[论文解读] Speech Robust Bench: A Robustness Benchmark For Speech Recognition
Introduction of Speech Robust Bench (SRB),一个用于 ASR 的综合鲁棒性基准,评估 69 种扰动并提供用于比较模型的指标,包括子群体公平性分析。
As Automatic Speech Recognition (ASR) models become ever more pervasive, it is important to ensure that they make reliable predictions under corruptions present in the physical and digital world. We propose Speech Robust Bench (SRB), a comprehensive benchmark for evaluating the robustness of ASR models to diverse corruptions. SRB is composed of 114 input perturbations which simulate an heterogeneous range of corruptions that ASR models may encounter when deployed in the wild. We use SRB to evaluate the robustness of several state-of-the-art ASR models and observe that model size and certain modeling choices such as the use of discrete representations, or self-training appear to be conducive to robustness. We extend this analysis to measure the robustness of ASR models on data from various demographic subgroups, namely English and Spanish speakers, and males and females. Our results revealed noticeable disparities in the model's robustness across subgroups. We believe that SRB will significantly facilitate future research towards robust ASR models, by making it easier to conduct comprehensive and comparable robustness evaluations.
研究动机与目标
- 推动在真实世界污染下对 ASR 模型进行鲁棒性评估。
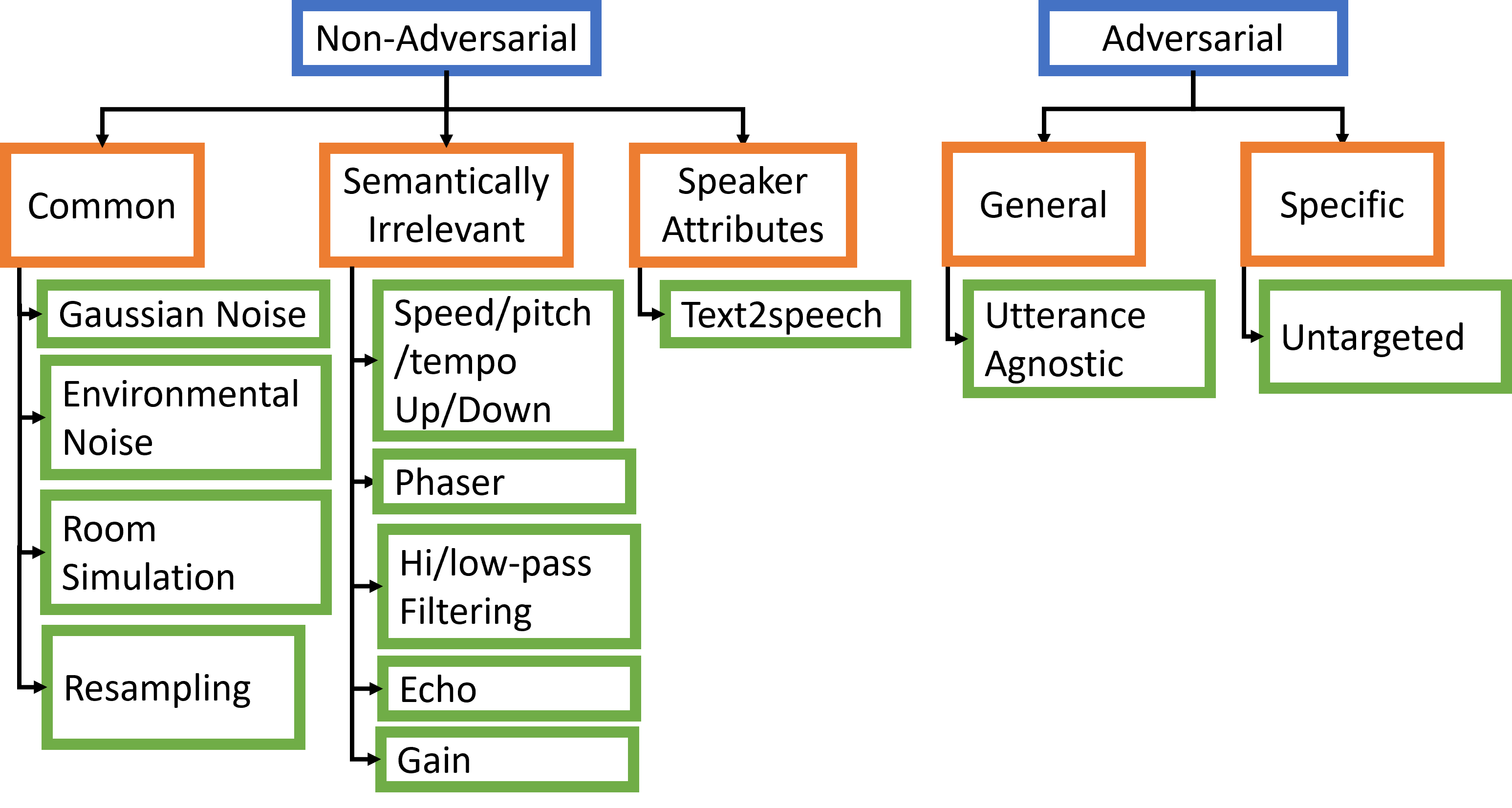
- 定义覆盖非对抗性和对抗性扭曲的全面扰动库。
- 提出用于评估 ASR 预测的效用与稳定性的指标(NWER 和 WERV)。
- 通过开源工具和数据集实现标准化、可扩展的鲁棒性评估。
提出的方法
- 构建覆盖环境、说话者相关、语义和对抗性扭曲的扰动库,涵盖四个严重度。
- 对扰动后的音频使用目标 ASR 模型和一个基线模型进行转录以计算指标。
- 通过用基线 WER 归一化目标 WER 来计算归一化词错误率(NWER),以考虑难度。
- 计算 WER 方差(WERV),以衡量在多个扰动样本上的预测稳定性。
- 以 Librispeech 作为主要数据集,并包含西班牙语子集数据以进行多语言分析。
- 开源 SRB 工具和扰动测试集,以实现开箱即用的鲁棒性评估。

实验结果
研究问题
- RQ1当前的 ASR 模型对广泛的现实世界扰动(非对抗性和对抗性)有多鲁棒?
- RQ2模型规模、架构和训练数据如何影响对扰动的鲁棒性?
- RQ3鲁棒性特征是否在语言(英语与西班牙语)和性别等人群子群体之间存在差异?
- RQ4SRB 能否揭示 ASR 鲁棒性在不同子群体之间的公平性或偏差差距?
主要发现
| 语言 | 模型 | 数据(h) | #参数(M) | WER |
|---|---|---|---|---|
| EN | wav2vec2-large-960h-lv60-self (w2v2-lg-slf) | 60,000 | 317 | 1.8 |
| EN | wav2vec2-large-robust-ft-libri-960h (w2v2-lg-rob) | 63,000 | 317 | 2.6 |
| EN | hubert-large-ls960-ft (hubt-lg) | 60,000 | 300 | 2.1 |
| EN | wav2vec2-base-960h (w2v2-bs) | 960 | 95 | 4.9 |
| EN | whisper-tiny.en (wsp-tn.en) | 680,000 | 39 | 6.4 |
| EN | deepspeech (ds) | 960 | 86 | 17.7 |
| ES | wav2vec2-large-xlsr-53-spanish (w2v2-lg-es) | 54,350 | 315 | 6.8 |
| ES | wav2vec2-base-10k-voxpopuli-ft-es (w2v2-bs-es) | 10,116 | 94 | 25.7 |
| Multi | whisper-large-v2 (wsp-lg) | 680,000 | 1,550 | 3.9/5.8 |
| Multi | whisper-tiny (wsp-tn) | 680,000 | 39 | 8.2/23.3 |
| Multi | mms-1b-fl102 (mms) | 55,000 | 964 | 15.4/15.7 |
- 大型模型平均上更鲁棒,但使用某些技术训练的小型模型在某些扰动上可能表现更好。
- Whisper large 和 Wav2Vec2.0 large 变体通常表现出较高的鲁棒性,但某些扰动更有利于较小的模型(如 RIR、重新采样、节奏减速)。
- 对抗性扰动揭示了模型间不同的鲁棒性特征;有些模型更能抵抗针对语言单元本身的攻击,有些模型更能抵抗一般性攻击。
- 西班牙语(非英语)在许多模型上的鲁棒性落后于英语,多语言模型在西班牙语数据上的鲁棒性通常较差。
- 鲁棒性存在性别差异,女性说话者对多种模型通常更困难,在某些扰动和对抗性攻击下这一差距会扩大。
- SRB 能进行详细的公平性分析,并揭示鲁棒性因语言和人口统计子群体而异的条件。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。