[论文解读] Speech2Vec: A Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
本文提出 Speech2Vec,一种基于序列到序列 RNN 的框架,可直接从原始语音中学习语义词嵌入,无需依赖转录文本。通过将 Word2Vec 的 skipgram 和连续词袋(CBOW)目标函数适配至音频,该方法捕捉了文本中缺失的语调和语义线索,在 13 项词相似度基准测试中表现优于基于文本的 Word2Vec,尤其在 50 维嵌入时表现更优。
In this paper, we propose a novel deep neural network architecture, Speech2Vec, for learning fixed-length vector representations of audio segments excised from a speech corpus, where the vectors contain semantic information pertaining to the underlying spoken words, and are close to other vectors in the embedding space if their corresponding underlying spoken words are semantically similar. The proposed model can be viewed as a speech version of Word2Vec. Its design is based on a RNN Encoder-Decoder framework, and borrows the methodology of skipgrams or continuous bag-of-words for training. Learning word embeddings directly from speech enables Speech2Vec to make use of the semantic information carried by speech that does not exist in plain text. The learned word embeddings are evaluated and analyzed on 13 widely used word similarity benchmarks, and outperform word embeddings learned by Word2Vec from the transcriptions.
研究动机与目标
- 开发一种直接从原始语音中学习语义词嵌入的方法,无需依赖文本转录。
- 克服基于自动语音识别(ASR)的词嵌入流水线的局限性,包括转录错误和语调信息的丢失。
- 通过将 Word2Vec 的 skipgram 和连续词袋(CBOW)训练目标适配至音频序列,将 Word2Vec 的成功扩展至语音领域。
- 评估从语音中学习的嵌入是否能捕捉比基于文本的对应方法更丰富的语义信息。
- 分析在不同词频和训练配置下,所学嵌入的稳定性和可变性。
提出的方法
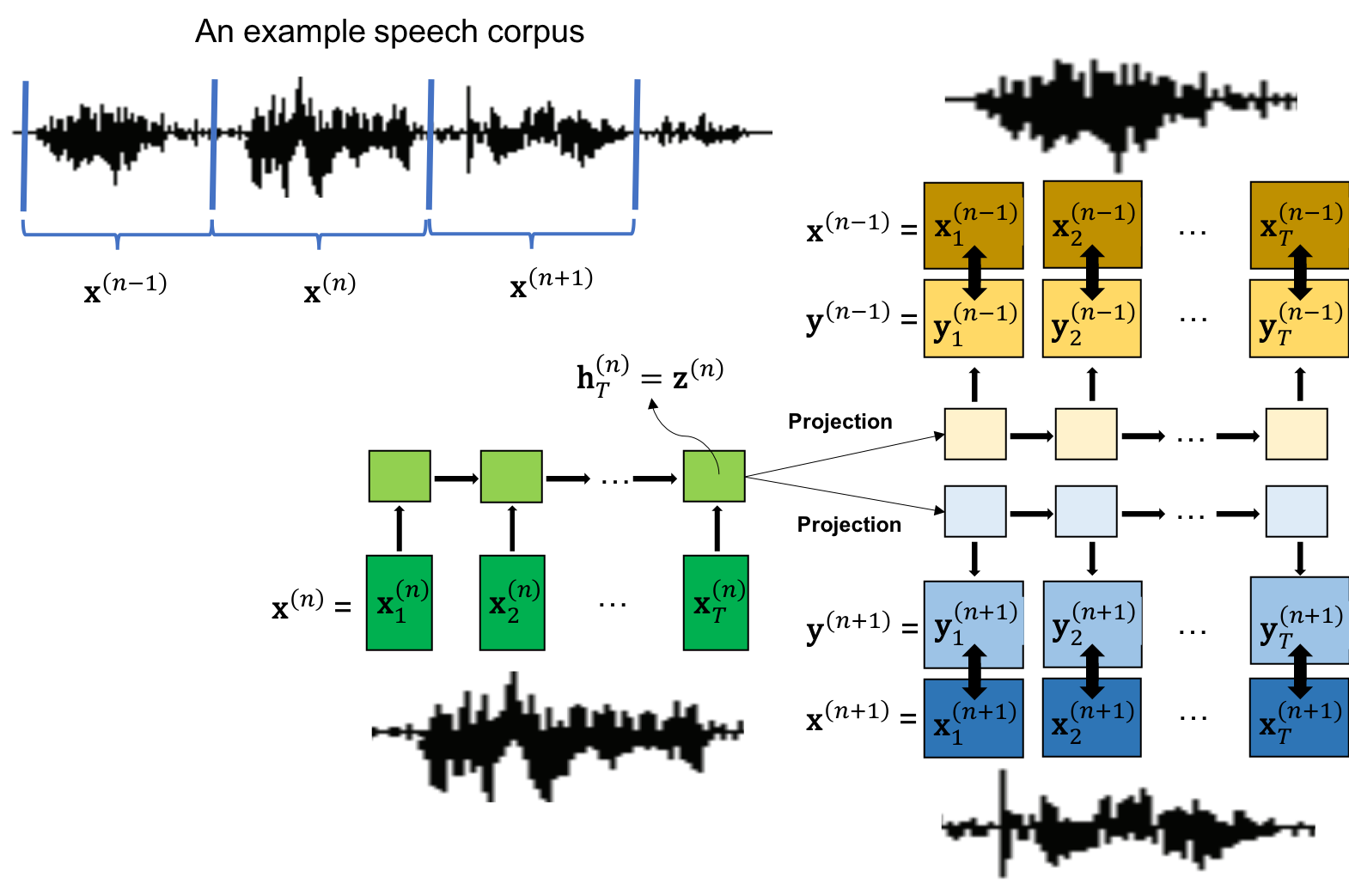
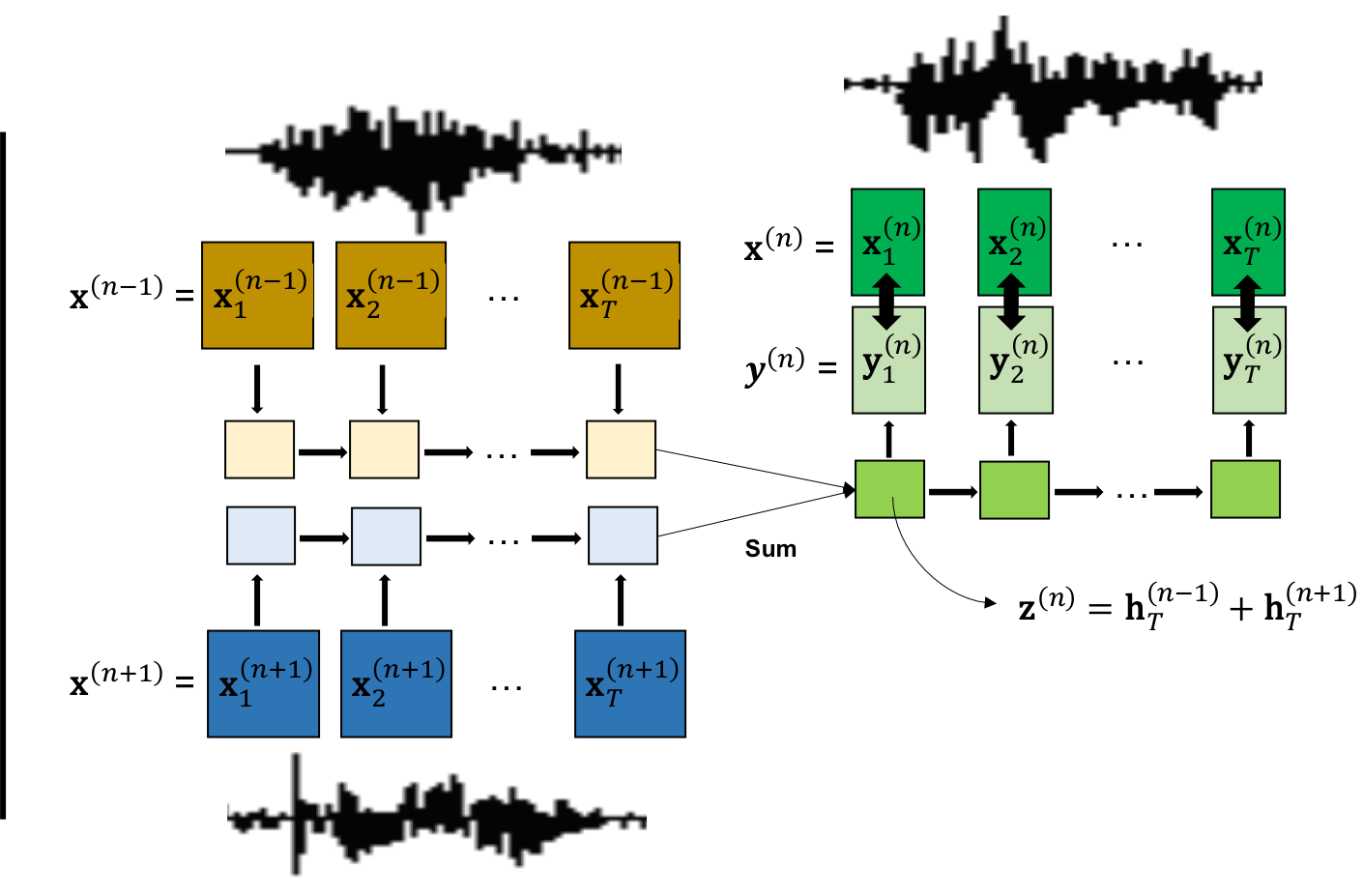
- Speech2Vec 使用双向 RNN 编码器-解码器框架,将可变长度的音频序列(如 MFCC)映射为固定长度的嵌入。
- 模型采用 skipgram 或连续词袋(CBOW)目标函数进行训练,即从词嵌入中预测目标词段的上下文。
- 对于 skipgram,编码器处理目标词段,解码器预测其周围的上下文段;对于 CBOW,编码器编码多个上下文段以预测目标。
- 音频段被填充至固定长度,并使用强制对齐获取词级边界,从而实现监督式分割。
- 模型通过交叉熵损失端到端训练,以最大化正确预测上下文段的可能性。
- 词嵌入由编码器的最终隐藏状态提取,并通过词相似度基准进行评估。
实验结果
研究问题
- RQ1序列到序列 RNN 框架能否在无需文本转录的情况下,直接从原始语音中学习有意义的语义词嵌入?
- RQ2从包含语调线索的语音中学习嵌入,是否能产生比从转录文本中学习更优的语义表征?
- RQ3Speech2Vec 的 skipgram 和 CBOW 变体在不同词频水平下的性能与稳定性如何比较?
- RQ4随着训练语料中某词出现次数的增加,其词嵌入的方差如何变化?
- RQ5所学嵌入在多大程度上能捕捉语义关系,如同义词与反义词?
主要发现
- 在 13 项词相似度基准中的 8 项上,skipgram 版本的 Speech2Vec 表现优于 CBOW 版本的 Speech2Vec 和基于文本的 Word2Vec,证明了其从语音中学习语义表征的优越性。
- 当使用 50 维嵌入时,Speech2Vec 在大多数基准上表现最佳,表明在直接从原始音频学习时,较小的嵌入维度已足够。
- 随着训练语料规模增大,Speech2Vec 的性能显著提升,尤其在从 10% 增加到完整训练数据时提升明显。
- 随着词频增加,skipgram 版本的 Speech2Vec 显示出更低的词嵌入方差,表明其对高频词具有更高的稳定性和鲁棒性。
- t-SNE 可视化结果证实,所学嵌入捕捉了语义结构,反义词(如正向/负向词)在空间上被分离,而同义词则被聚类在一起。
- 该模型能够捕捉语音中的语调和上下文线索,从而在语义泛化能力上优于基于文本的 Word2Vec,即使在使用转录文本作为输入时亦是如此。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。