[论文解读] SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks
SpeechPrompt v2 使用提示微调和可学习的口头化器,在最少可训练参数的情况下实现广泛的语音分类任务,并在多语言和多任务中达到具有竞争力或最先进的结果。
Prompt tuning is a technology that tunes a small set of parameters to steer a pre-trained language model (LM) to directly generate the output for downstream tasks. Recently, prompt tuning has demonstrated its storage and computation efficiency in both natural language processing (NLP) and speech processing fields. These advantages have also revealed prompt tuning as a candidate approach to serving pre-trained LM for multiple tasks in a unified manner. For speech processing, SpeechPrompt shows its high parameter efficiency and competitive performance on a few speech classification tasks. However, whether SpeechPrompt is capable of serving a large number of tasks is unanswered. In this work, we propose SpeechPrompt v2, a prompt tuning framework capable of performing a wide variety of speech classification tasks, covering multiple languages and prosody-related tasks. The experiment result shows that SpeechPrompt v2 achieves performance on par with prior works with less than 0.15M trainable parameters in a unified framework.
研究动机与目标
- Motivate the need for parameter-efficient, unified speech classification with prompting.
- Develop a prompting framework that works across content and prosody tasks and multiple languages.
- Reduce trainable parameters while maintaining competitive performance.
- Introduce a learnable verbalizer to improve mapping from LM outputs to task labels.
- Evaluate generalization and limitations across a broad task suite.
提出的方法
- Use fixed pre-trained spoken LMs (GSLM and pGSLM) as backbones with frozen parameters.
- Learn small task-specific prompt vectors that are concatenated with input embeddings and used in deep prompting of Transformer layers.
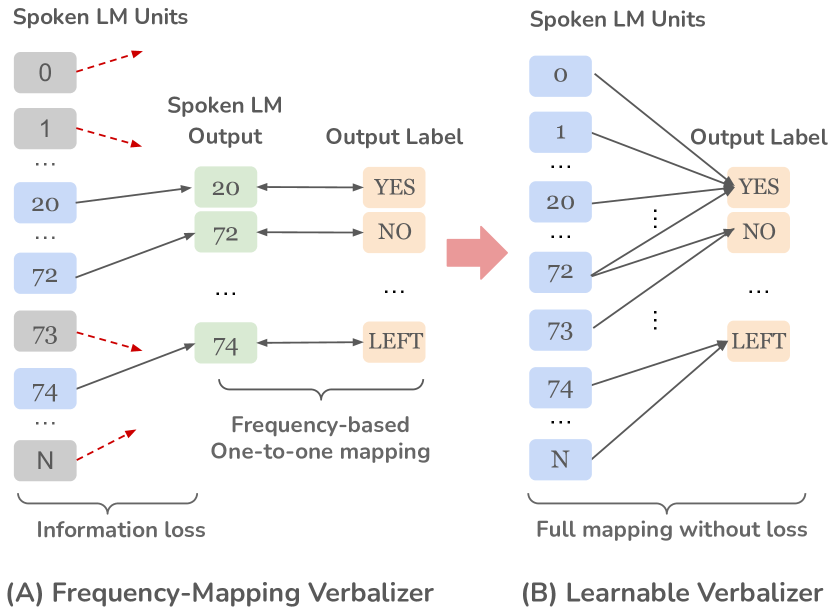
- Apply a learnable verbalizer (a linear model) to map LM output distributions to task labels, jointly trained with prompts.
- No task-specific hyperparameter tuning; fixed prompt length (l=5) and prompt size (~0.128M parameters).
- Evaluate on 10 speech classification tasks from 14 datasets spanning multiple languages and speech properties.
- Compare with SOTA under fully supervised and pre-train/fine-tune paradigms.
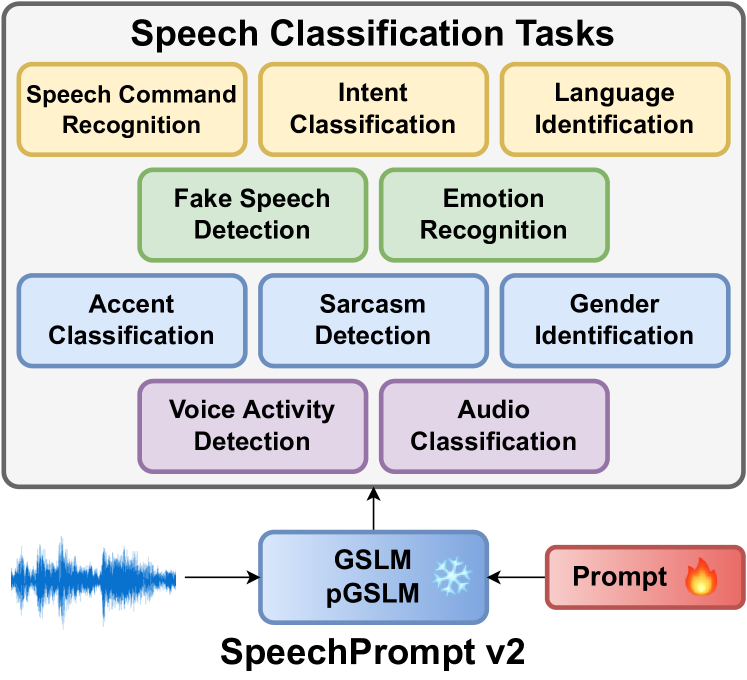
实验结果
研究问题
- RQ1Can SpeechPrompt v2 achieve competitive performance across a wide range of speech classification tasks with minimal trainable parameters?
- RQ2Does a learnable verbalizer consistently improve prompting performance in speech LMs?
- RQ3How does SpeechPrompt v2 perform across content-related vs. prosody-related tasks and across languages?
- RQ4What are the limitations and stability concerns of prompt tuning in non-English or diverse speech datasets?
主要发现
- SpeechPrompt v2 achieves competitive performance and, in some cases, state-of-the-art results on several tasks (e.g., Lithuanian SCR, Arabic SCR, Sarcasm Detection).
- The framework is highly parameter-efficient, with under 0.1% of the spoken-LM parameters trainable per task (~0.15M).
- A learnable verbalizer improves performance in most tasks with GSLM, and generally helps explainability via SHAP analyses of unit-to-label mappings.
- Prompt tuning shows some instability and performance variance, especially on non-English or highly diverse speech data; no per-task hyperparameter optimization was performed.
- Prompting enables a unified, simplified pipeline that can approach or match SOTA on a wide suite of speech classification tasks, though some tasks still lag behind fully supervised or pre-train/fine-tune methods.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。