[论文解读] Stable LM 2 1.6B Technical Report
Stable LM 2 1.6B 是一个开放的解码器仅型语言模型,具有1.6B参数,在透明的多语言数据混合上训练,并以量化和边缘设备吞吐能力发布,同时提供微调和评估结果。
We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruction-tuned versions of StableLM 2 1.6B. The weights for both models are available via Hugging Face for anyone to download and use. The report contains thorough evaluations of these models, including zero- and few-shot benchmarks, multilingual benchmarks, and the MT benchmark focusing on multi-turn dialogues. At the time of publishing this report, StableLM 2 1.6B was the state-of-the-art open model under 2B parameters by a significant margin. Given its appealing small size, we also provide throughput measurements on a number of edge devices. In addition, we open source several quantized checkpoints and provide their performance metrics compared to the original model.
研究动机与目标
- 解释用于构建 Stable LM 2 1.6B 的数据收集与训练过程。
- 描述预训练架构、分词器与优化设置。
- 详细说明用于提升对话能力的微调、对齐与自我知识技术。
- 展示在少-shot、多语言以及多轮对话基准上的全面评估。
- 提供关于推理、量化选项、边缘设备吞吐量和环境影响的信息。
提出的方法
- 使用 FlashAttention-2 和混合精度,对 1.6B 解码器-仅 Transformer,具 4096 token 上下文进行训练。
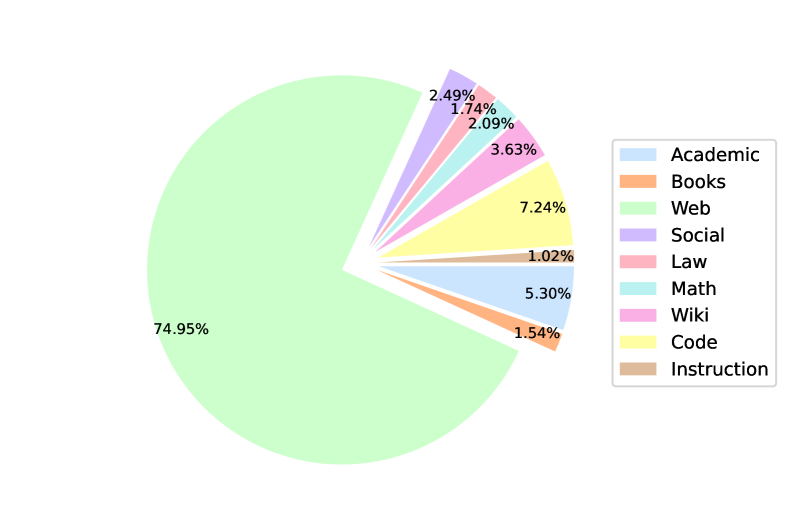
- 使用总量约为 2 万亿令牌的多语言数据混合,并对领域和语言设定显式采样权重(表 1)。
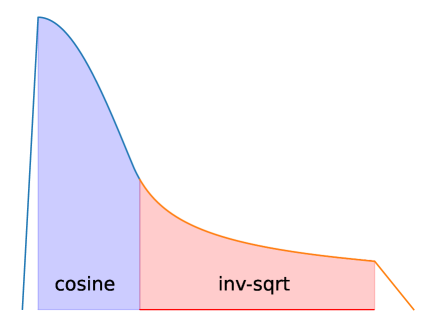
- 采用分阶段学习率计划,含热身、余弦与 rsqrt 衰减,随后线性冷却。
- 在 Hugging Face Hub 的指令数据集上进行监督微调,然后进行 Direct Preference Optimization 和自我知识训练循环。
- 提供并发布量化检查点,格式为 Q4_0、Q4_1、Q5_K_M GGUF 与 INT4,适用于各种推理框架。
实验结果
研究问题
- RQ1与同等规模的开源模型相比,Stable LM 2 1.6B 在标准少样本与零样本基准测试中的表现如何?
- RQ2多语言预训练数据对非英语及多语言基准的影响是什么?
- RQ3SFT、DPO 与自我知识训练如何影响对话质量与对齐?
- RQ4边缘部署的设备吞吐量与量化权衡是什么?
- RQ5发布一个开放权重模型的环境影响与社会考量是什么?
主要发现
- Stable LM 2 1.6B 在多项英语基准测试上优于同等规模的其他基础模型,在对话场景下接近更大模型的 MT-Bench。
- 在非英语评估设置中,该模型在德语、西班牙语、法语、意大利语、葡萄牙语和荷兰语等多语言能力方面表现强劲。
- 指令微调变体(stablelm-2-1_6b-dpo)在若干指标上优于 Phi-1.5,并与 Phi-2 相比表现良好。
- 提供并发布量化检查点(Q4_0、Q4_1、Q5_K_M GGUF、INT4),能够实现高效的设备端或特定框架部署。
- 通量测量显示在边缘设备上使用更低精度时有 substantial gains,提供了各框架的示例图。
- 训练约需 92,000 小时 GPU 工作量,产生了估计 11 tCO2eq 的碳足迹。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。