[论文解读] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
本论文提出 Stable Video Diffusion (SVD),一个在精选的大规模视频数据集上通过三阶段数据策略训练的潜在视频扩散模型,达到最先进的文本到视频和图像到视频合成,具备强大的运动和多视角先验。
We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .
研究动机与目标
- 识别用于大规模视频扩散预训练的有效数据筛选策略。
- 提出并验证适用于视频 LDM 的三阶段训练方案(图像预训练、视频预训练、高质量微调)。
- 证明经过筛选的预训练能够得到强大的运动表示,并惠及下游任务,包括文本到视频、图像到视频以及多视角生成。
- 表示基础模型作为稳健的运动先验,并且可以高效地对多种任务进行微调(例如用于相机运动的 LoRA)。
提出的方法
- 使用将时间层插入预训练图像扩散主干的潜在视频扩散模型。
- 构建一个系统性数据筛选工作流,包括切片检测、合成字幕、光流过滤、OCR,以及基于 CLIP 的美学和相似性度量。
- 分三阶段训练:(i) 在二维扩散模型上进行图像预训练,(ii) 以低分辨率进行大规模视频预训练,(iii) 在较小数据集上以高分辨率进行高质量微调。
- 将 EDM 噪声计划向更高噪声值倾斜,以改善高分辨率微调。
- 通过帧率微条件和用于相机运动的 LoRA 模块实现运动控制。
- 通过在多视图数据集上微调来实现多视图生成,以创建一致的多视图输出,利用所学的运动先验。
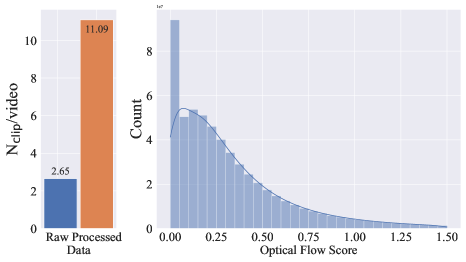
实验结果
研究问题
- RQ1精心筛选的大型视频语料库是否在微调后提升最终视频模型的性能?
- RQ2三阶段训练方案对高质量文本到视频与图像到视频合成的影响是什么?
- RQ3基础视频模型是否能够提供强大的运动表示以及用于下游任务的可用 3D/多视角先验?
- RQ4在质量和效率方面,基于精选数据预训练的视频扩散模型与最先进的多视角/合成方法相比如何?
主要发现
- 在经过精心筛选的视频数据上进行预训练可获得显著的性能提升,这种提升在高质量微调后仍然存在。
- 使用精选数据进行预训练的基础模型在零-shot 文本到视频上表现出色,在 UCF-101 上超越了多个基线。
- 在高质量数据上的微调产生与闭源模型竞争的高分辨率文本到视频和图像到视频结果。
- 基础模型提供强大的运动表示,并作为下游多视角生成的强大先验,在多视角任务中超越如 Zero123XL 和 SyncDreamer 等方法。
- 使用 LoRA 模块实现图像到视频生成中的显式相机运动控制。
- 三阶段训练策略能有效扩展到大型数据集(约 600M 样本),并在有限的计算资源下实现高效的多视角微调。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。