[论文解读] StarCoder: may the source be with you!
StarCoderBase 和 StarCoder 是开放获取的 15.5B 代码 LLM,具备 8K 上下文,训练自 The Stack,实现强劲的开放模型性能,并达到或超过 OpenAI 的 code-cushman-001,同时为开放发布提供安全性与归因工具。
The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
研究动机与目标
- 开发具备广泛语言支持的开放获取代码 LLMs(StarCoderBase 和 StarCoder)。
- 在 The Stack 的宽松许可数据上进行训练,并对数据进行仔细整理。
- 对开放与闭源代码 LLM 进行全面评估,并评估安全工具。
- 通过归因追踪、改进的个人可识别信息(PII)删减,以及可获取的许可,促进负责任的部署。
- 在有文档的前提下,以具有商业可行性的开放许可证公开发布模型。
提出的方法
- 我们使用具备 15.5B 参数、8K 令牌上下文和 Fill-in-the-Middle 的中间填充能力的模型。
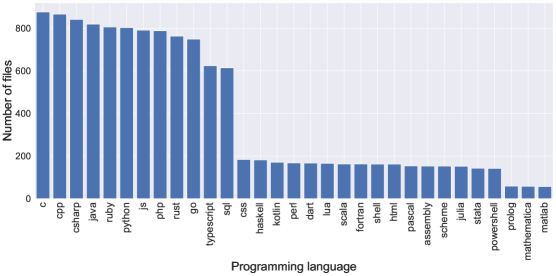
- StarCoderBase 在 The Stack 的 1 万亿标记,覆盖 80+ 种语言、GitHub 问题、提交和笔记本进行训练。
- StarCoder 是一个在额外 35B Python 标记上进行微调的变体。
- 我们通过 Multi-Query-Attention 实现快速大批量推理。
- 数据整理过滤包括语言选择、XML/HTML/JSON/YAML 处理,以及 Jupyter 笔记本处理。
- 对代码数据应用去重管道(MinHashes 和 LSH);对提交的数据量进行采样。
- 通过专用数据集和 StarEncoder 模型增强 PII 区删减;一个归因工具被整合到 VSCode 演示中,用于训练数据追溯。
实验结果
研究问题
- RQ1How do StarCoderBase and StarCoder compare to open Code LLMs across multi-language support?
- RQ2Do StarCoderBase and StarCoder match or surpass OpenAI code-cushman-001 in evaluation benchmarks?
- RQ3Does fine-tuning on Python give StarCoder an edge over other Python-tuned models while preserving cross-language performance?
- RQ4Can open-access releases be made safe and transparent via attribution tools and improved PII redaction?
主要发现
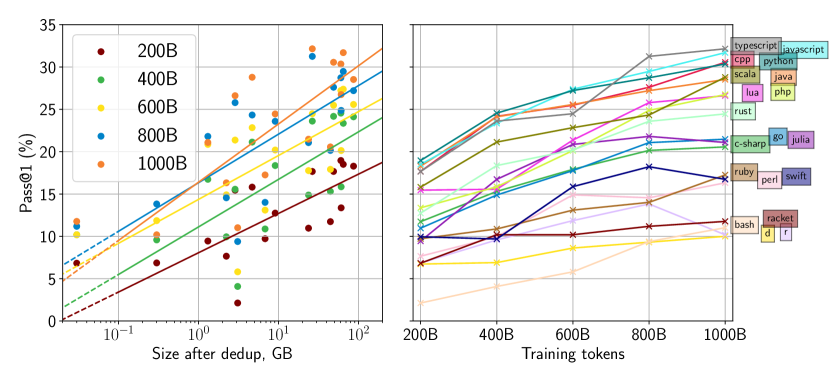
- StarCoderBase outperforms every open LLM that supports multiple programming languages.
- StarCoderBase matches or outperforms the OpenAI code-cushman-001 model.
- When fine-tuned on Python, StarCoder substantially outperforms existing Python-tuned LLMs.
- StarCoder outperforms every model that is fine-tuned on Python while retaining performance across other languages.
- The release includes OpenRAIL-M licensing, an attribution tracing tool, and an improved PII redaction pipeline with a trained StarEncoder.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。