[论文解读] Statler: State-Maintaining Language Models for Embodied Reasoning
Statler 引入一个框架,其中成对的世界状态读取者与写入者语言模型明确地维护并更新估计的世界状态,以引导具身机器人规划,在模拟与真实机器人上的长期任务中,相较 Code-as-Policies 显示出显著提升。
There has been a significant research interest in employing large language models to empower intelligent robots with complex reasoning. Existing work focuses on harnessing their abilities to reason about the histories of their actions and observations. In this paper, we explore a new dimension in which large language models may benefit robotics planning. In particular, we propose Statler, a framework in which large language models are prompted to maintain an estimate of the world state, which are often unobservable, and track its transition as new actions are taken. Our framework then conditions each action on the estimate of the current world state. Despite being conceptually simple, our Statler framework significantly outperforms strong competing methods (e.g., Code-as-Policies) on several robot planning tasks. Additionally, it has the potential advantage of scaling up to more challenging long-horizon planning tasks.
研究动机与目标
- 通过在 LLCs 中显式维护世界状态来推进并实现长期 robotic 规划的动机与能力。
- 开发一种基于模型的方法,使用世界状态读取者和写入者对动作进行当前状态条件化。
- 展示状态维护在模拟桌面域和真实机器人中的鲁棒性与可扩展性。
提出的方法
- 提示两个专门的 LLM:一个世界状态读取者,根据查询与当前状态生成可执行动作;一个世界状态写入者,在执行动作后更新状态。
- 维护一个外部的、JSON 格式的世界状态表示,在各步骤中读取并更新,以跟踪潜在动态。
- 使用演示来训练或引导读取/写入提示;可选比较统一配置与分离的读取者/写入者配置。
- 在多台桌面操作任务上,将 Statler 与 CaP(Code-as-Policies)以及 CaP 配合 Chain-of-Thought 提示进行对比评估。
- 展示消融实验,显示分离的读取者/写入者组件的贡献以及不同状态维护策略的重要性。
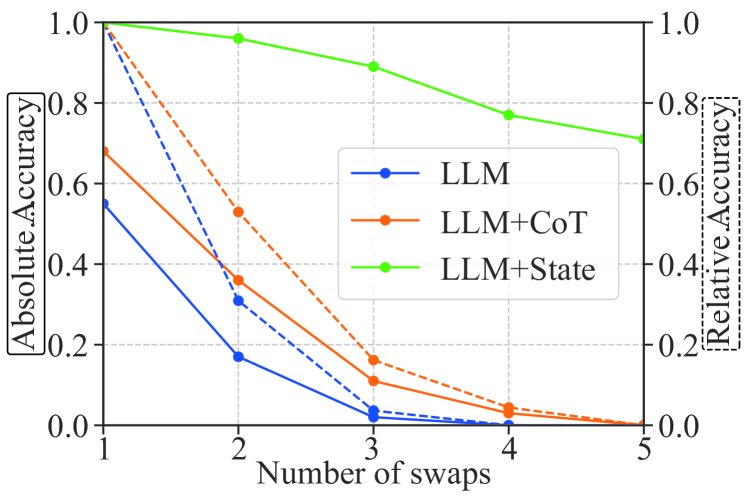
实验结果
研究问题
- RQ1相对于无状态策略,显式、维护中的世界状态是否能改善多步机器人规划?
- RQ2在长期任务中,分离的世界状态读取者和写入者是否比统一 prompting 提供可衡量的收益?
- RQ3在对过去交互进行推理时,Statler 在模拟域与真实机器人实验中的表现有何差异?
- RQ4状态维护消融对任务成功率和每步精度有何影响?
主要发现
- Statler 在仿真中的拾取放置、消毒和重量推理任务上显著优于 CaP 与 CaP+CoT。
- 非时序查询对 CaP 近乎完美,但时序查询 CaP 会崩溃;Statler 在基于记忆的问题上保持高性能。
- 在真实机器人实验中,Statler 的回合与步骤成功率高于 CaP,LLM 推理是主要的失败来源(感知/操作也有贡献)。
- 消融显示保持独立的世界状态读取者和写入者比统一模型具有更好性能,且状态维护对完成回合至关重要。
- Statler 展示了跨域的鲁棒性,并有望扩展到更长时域的规划任务。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。