[论文解读] Strategic Reasoning with Language Models
该论文表明,使用系统生成的提示来结构化搜索、价值分配和信念跟踪,可以使预训练语言模型在矩阵与谈判博弈中执行灵活的战略推理,从而通过少量示例实现对新博弈和目标的泛化。
Strategic reasoning enables agents to cooperate, communicate, and compete with other agents in diverse situations. Existing approaches to solving strategic games rely on extensive training, yielding strategies that do not generalize to new scenarios or games without retraining. Large Language Models (LLMs), with their ability to comprehend and generate complex, context-rich language, could prove powerful as tools for strategic gameplay. This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstrations of reasoning about states, values, and beliefs to prompt the model. Using extensive variations of simple matrix games, we show that strategies that are derived based on systematically generated prompts generalize almost perfectly to new game structures, alternate objectives, and hidden information. Additionally, we demonstrate our approach can lead to human-like negotiation strategies in realistic scenarios without any extra training or fine-tuning. Our results highlight the ability of LLMs, guided by systematic reasoning demonstrations, to adapt and excel in diverse strategic scenarios.
研究动机与目标
- 激励并解决AI代理在新战略情景中的泛化差距。
- 提出一种基于提示的方法,使LLM具备战略规划能力。
- 通过少量示例实现对新颖博弈结构、目标和部分信息的泛化。
- 在现实情景中展示类似人类的谈判行为且无需再训练。
提出的方法
- 开发一个自动化的提示编译器,生成战略推理(搜索、价值分配、信念跟踪)示例。
- 使用上下文示例通过链式推理提示在行动选择前对LLM进行偏置。
- 在矩阵博弈中,改变奖励、参与者、可观测性和回合数以测试泛化性。
- 在谈判博弈中,对人类示例进行注释,以引导模型在价值和信念方面的推理。
- 结合工具(搜索和计算)在上下文限制内管理大规模决策空间和复杂推理。
- 以多种LLM(code-davinci-002及若干文本模型)进行评估,与基线和消融对比。
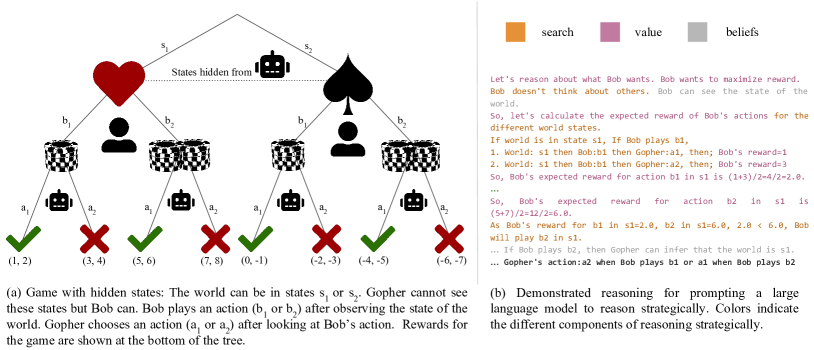
实验结果
研究问题
- RQ1LLMs是否能利用系统生成的提示将战略推理泛化到新的博弈结构和目标?
- RQ2将推理分解为搜索、价值分配和信念跟踪是否能提升相对于普通提示的可靠性?
- RQ3LLMs在无需额外训练的现实情景中是否能与人类进行谈判并表现出类似人类的行为?
- RQ4部分可观测性和信息变动如何影响模型的战略推理与信念形成?
主要发现
- 结构化搜索、价值分配和信念跟踪的提示能够实现对新收益和博弈结构的泛化。
- 分解式推理在对新博弈结构和部分信息的泛化方面几近完美,优于基线提示与消融。
- 该方法在不重新训练的情况下,支持接近人类的现实性和质量的谈判行为。
- LLMs能够以零-shot方式在演示的帮助下适应新目标(如最大化福利或自定义 daxity 指标)。
- 迭代推理提升了谈判公平性指标,优于未形成信念的Deal 或 No Deal情景中的模型。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。