[论文解读] Structured prompt interrogation and recursive extraction of semantics (SPIRES): A method for populating knowledge bases using zero-shot learning
SPIRES 使用零样本学习,采用灵活、模式驱动的提示方法来提取并将嵌套知识绑定到知识库的实体标识符,使用开源的 OntoGPT 实现,并具备强健的定位能力。它能够在没有训练数据的情况下支持新任务,并利用本体进行标识符定位。
Creating knowledge bases and ontologies is a time consuming task that relies on a manual curation. AI/NLP approaches can assist expert curators in populating these knowledge bases, but current approaches rely on extensive training data, and are not able to populate arbitrary complex nested knowledge schemas. Here we present Structured Prompt Interrogation and Recursive Extraction of Semantics (SPIRES), a Knowledge Extraction approach that relies on the ability of Large Language Models (LLMs) to perform zero-shot learning (ZSL) and general-purpose query answering from flexible prompts and return information conforming to a specified schema. Given a detailed, user-defined knowledge schema and an input text, SPIRES recursively performs prompt interrogation against GPT-3+ to obtain a set of responses matching the provided schema. SPIRES uses existing ontologies and vocabularies to provide identifiers for all matched elements. We present examples of use of SPIRES in different domains, including extraction of food recipes, multi-species cellular signaling pathways, disease treatments, multi-step drug mechanisms, and chemical to disease causation graphs. Current SPIRES accuracy is comparable to the mid-range of existing Relation Extraction (RE) methods, but has the advantage of easy customization, flexibility, and, crucially, the ability to perform new tasks in the absence of any training data. This method supports a general strategy of leveraging the language interpreting capabilities of LLMs to assemble knowledge bases, assisting manual knowledge curation and acquisition while supporting validation with publicly-available databases and ontologies external to the LLM. SPIRES is available as part of the open source OntoGPT package: https://github.com/ monarch-initiative/ontogpt.
研究动机与目标
- 实现从自然语言文本中自动填充复杂、嵌套的知识模式,无需任务特定的训练数据。
- 利用大语言模型进行基于提示的提取,同时将实体绑定到外部本体中的持久标识符。
- 提供一个灵活的、模式驱动的框架,能够处理嵌套的属性结构并支持翻译为OWL以进行推理。
- 在多个领域展示SPIRES的应用,并将定位准确性与基线LLM提示进行比较。
提出的方法
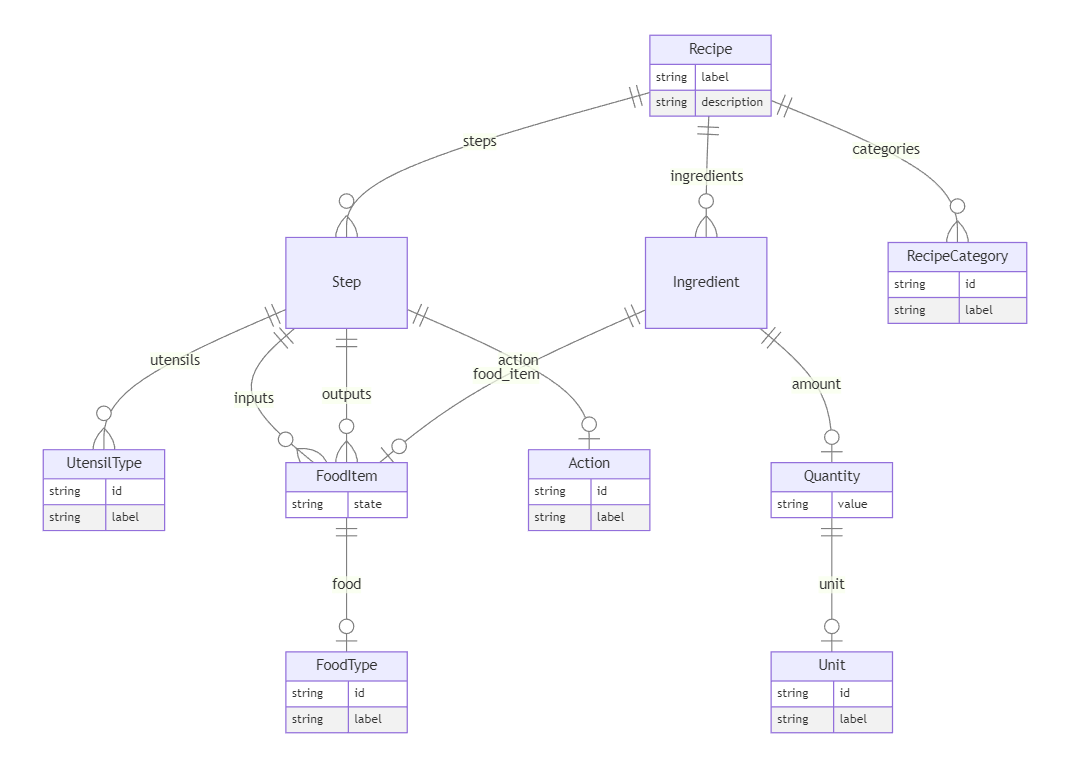
- 将知识模式S定义为一组具有属性和值域的类,包括多值属性和内联的嵌套类。
- 从S、目标类C和输入文本T生成结构化提示p,使用伪YAML属性模板和TextIntro块。
- 查询LLM以完成提示并获得结构化形式的响应r。
- 解析r以递归地填充符合S的实例i,将叶节点实体通过本体(如FOODON、Wikidata)和工具(Gilda、OGER)定位到标识符。
- 可选地将填充的实例翻译为OWL,并使用OWL工具(ROBOT、Elk)进行推理。
- 提供基于OntoGPT的Python实现,使用LinkML进行模式定义,使用OAKlib进行定位,并提供多个领域的预制模式。
实验结果
研究问题
- RQ1SPIRES 是否能够在没有任何训练数据的情况下从非结构化文本中填充任意嵌套的知识模式?
- RQ2与纯LLM提示相比,SPIRES 在将实体定位到持久化本体标识符方面的提升程度如何?
- RQ3在将实体定位到MeSH/本体时,SPIRES 在既定的生物医学关系抽取任务上的表现如何?
- RQ4在多样化领域(食谱、信号通路、疾病治疗等)中的可行性与准确性如何?
主要发现
- SPIRES 取得了高水平的定位准确性,例如在GPT-3.5-turbo下对100个GO术语的定位中有98个正确,在GPT-4-turbo下有97个正确。
- 在没有SPIRES的情况下,GPT-3.5-turbo经常对GO术语给出近乎全错的标识符,显示出在无定位的情况下的大规模幻觉。
- 在EMAPA本体上,SPIRES在GPT-3.5-turbo下对全部100个术语给出正确标识符,而GPT-4-turbo则在某些本体上持续拒绝定位。
- 在BioCreative Chemical-Disease Relation任务中,采用分块的SPIRES在GPT-3.5-turbo下的F=41.16 (P=0.43, R=0.39),不分块时F=36.64 (P=0.63, R=0.26);GPT-4-turbo则达到F=43.80 (P=0.69, R=0.32)。
- 使用GPT-3.5-turbo的SPIRES在BC5CDR上表现混合但具有竞争力,略低于使用训练数据的18支队伍的平均水平;GPT-4-turbo表现出不同的定位行为。
- 定位显著提升,显著优于仅提示的方法,支持零样本、模式驱动的知识库填充在无需新训练数据的情况下的可行性。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。