[论文解读] Studying LLM Performance on Closed- and Open-source Data
本文比较了 OpenAI Codex 风格的 LLM 在开源与微软等大型厂商的闭源代码上的代码补全、摘要与生成任务,针对 C# 与 C++ 的差异发现:C# 差异几乎不存在,但在闭源数据上 C++ 的性能显著下降;少量示例学习和 BM25 检索到的示例可以在一定程度上缓解差距。
Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
研究动机与目标
- 评估在开源数据训练的 LLM 在来自大型软件厂商(微软)的专有闭源代码上应用时是否表现相似。
- 通过比较 OSS 与闭源数据集在 C# 与 C++ 上的差异,评估语言特异性差异。
- 探究性能差距的潜在原因以及少-shot 的上下文学习或基于检索的示例是否能缩小差距。
- 探索 OSS 示例是否通过上下文学习技术提升对闭源代码的性能。
提出的方法
- 使用两种现成的 LLM(Code-Davinci-002 和 GPT-3.5-Turbo)不进行微调。
- 评估 CodeXGLUE 套件中的四个任务:标记完成、逐行完成、代码摘要和代码生成。
- 比较 C# 与 C++ 在 OSS 与闭源数据上的表现。
- 对代码摘要与代码生成应用少量示例学习,随机选择样本以及使用 BM25 棢取的样本作为示例。
- 使用精确匹配、BLEU 变体、ROUGE-L、METEOR,以及编辑距离相似度作为评估指标;在可用的情况下报告统计检验。
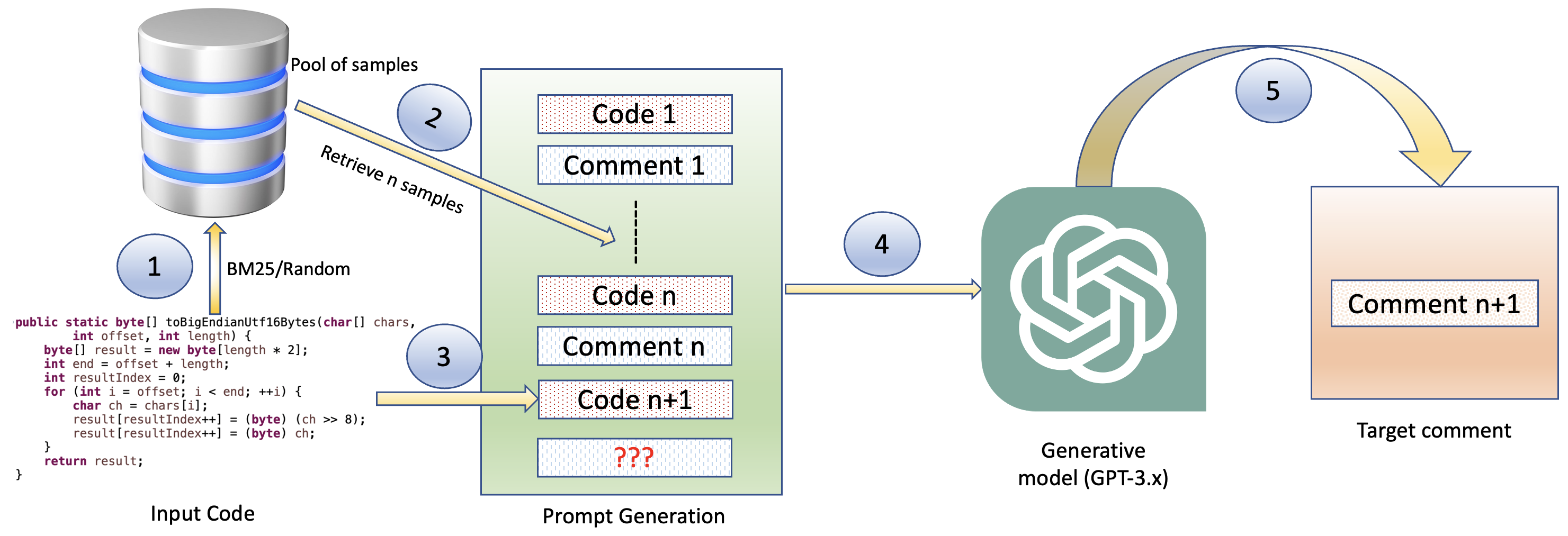
实验结果
研究问题
- RQ1RQ1: 在研究的语言和任务中,LLMs 在开源与闭源数据上是否表现不同?
- RQ2RQ2: 使用开源示例进行少量学习是否能提升闭源数据上的性能?
- RQ3RQ3: 在 OSS 和闭源数据中,C# 与 C++ 的观察到的性能差异原因是什么?
主要发现
- 对标记完成任务,C# 在 Code-Davinci-002 条件下未显示显著的 OSS 与闭源差异(OSS 71.32%,闭源 71.59%,p=0.67)。
- 对于 C++ 的标记完成,在 Code-Davinci-002 下 OSS(71.93%)到闭源(64.42%)存在显著下降(p<0.01)。
- 逐行完成呈现相同的语言差异:C# 显示无显著的 OSS 与闭源差异;C++ 在闭源性能上显示显著下降。
- 在少量学习和 BM25 棢取样本的条件下,C# 的代码摘要通常能够缩小 OSS 与闭源的差距,BM25 提供了一些增益;对于 C++,差距仍在,并且在使用 BM25 时可能被放大,取决于模型。
- 相比摘要,代码生成通常表现不如摘要,在 C++ 的 OSS 与闭源之间差距更大,即使采用少量学习。
- 总体而言,C# 在 OSS/闭源上表现稳定;C++ 在闭源数据上表现出显著下降,BM25 棢取的少量示例可以缓解部分差距,但并非全部。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。