[论文解读] Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4
论文提出了 Suspicion-Agent,一种基于 GPT-4 的代理,使用结构化提示和心智理论推理在不进行专门训练的情况下博弈不完美信息游戏,在 Leduc Hold’em 展现出具竞争力的表现,并在多种游戏中取得定性成功。
Unlike perfect information games, where all elements are known to every player, imperfect information games emulate the real-world complexities of decision-making under uncertain or incomplete information. GPT-4, the recent breakthrough in large language models (LLMs) trained on massive passive data, is notable for its knowledge retrieval and reasoning abilities. This paper delves into the applicability of GPT-4's learned knowledge for imperfect information games. To achieve this, we introduce extbf{Suspicion-Agent}, an innovative agent that leverages GPT-4's capabilities for performing in imperfect information games. With proper prompt engineering to achieve different functions, Suspicion-Agent based on GPT-4 demonstrates remarkable adaptability across a range of imperfect information card games. Importantly, GPT-4 displays a strong high-order theory of mind (ToM) capacity, meaning it can understand others and intentionally impact others' behavior. Leveraging this, we design a planning strategy that enables GPT-4 to competently play against different opponents, adapting its gameplay style as needed, while requiring only the game rules and descriptions of observations as input. In the experiments, we qualitatively showcase the capabilities of Suspicion-Agent across three different imperfect information games and then quantitatively evaluate it in Leduc Hold'em. The results show that Suspicion-Agent can potentially outperform traditional algorithms designed for imperfect information games, without any specialized training or examples. In order to encourage and foster deeper insights within the community, we make our game-related data publicly available.
研究动机与目标
- 利用预训练大型语言模型在不进行任务特定训练的情况下处理不完美信息博弈的动机与意义.
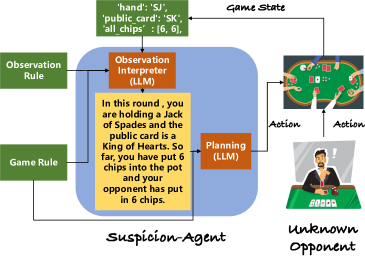
- 提出一个模块化的基于提示的架构,支持观测解释、规则理解与规划。
- 将心智理论(ToM)推理引入,以预测并影响对手行为。
- 证明在多种博弈上的泛化能力,并与传统不完美信息算法进行对比。
提出的方法
- 将博弈求解拆解为若干模块:观测解释器、游戏规则理解、规划、反思、评估。
- 将低层级的博弈状态转换为自然语言描述,以供 GPT-4 使用。
- 采用带反思的标准规划流程,通过历史经验学习并制定行动计划。
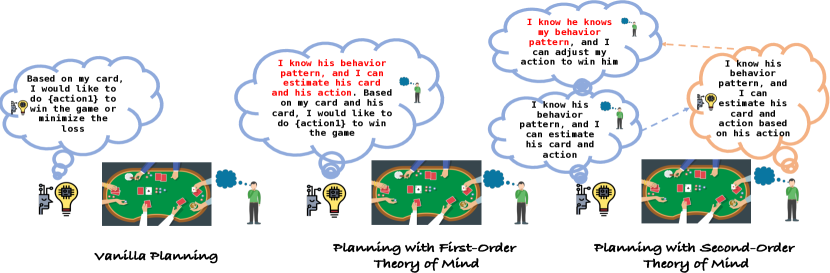
- 引入一阶和二阶 ToM 规划以预测对手行为并调整计划。
- 实施包含 ToM 的规划,估计对手牌力与对计划的可能应答。
- 在三个两人博弈上进行定性评估,并在 Leduc Hold’em 上对 CFR、NFSP、DMC、DQN 进行定量对比。
实验结果
研究问题
- RQ1Suspicion-Agent 能否在不进行专门训练的情况下赶上或超越传统的不完美信息算法?
- RQ2ToM(第一阶与第二阶)如何影响对不同对手的性能?
- RQ3基于 GPT-4 的方法是否能泛化到除 Leduc Hold’em 之外的多种不完美信息博弈?
- RQ4将对手观察和事后信息纳入对性能有何影响?
- RQ5不同的 ToM 顺序在策略有效性方面的比较如何?
主要发现
- 在所展示的实验中,Suspicion-Agent(由 GPT-4 提供支持)优于在 Leduc Hold’em 上专门训练的基线方法。
- 基于 GPT-4 的具 ToM 规划的代理对多样化对手策略(CFR、DMC、NFSP)的适应性优于普通规划。
- 在相同设置下,GPT-4(GPT-4)显著优于 GPT-3.5,而 GPT-3.5 的性能有明显下降。
- 二阶 ToM 规划能推动更具进攻性与剥削性的策略(如虚张声势),在面对易虚张声势的对手时获得更高的筹码收益。
- 定性结果表明在无需额外训练或示例的情况下,方法可泛化至 Coup 与 Texas Hold’em Limit。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。