[论文解读] SVIT: Scaling up Visual Instruction Tuning
SVIT 构建一个 4.2 百万指令数据集用于视觉指令微调,并展示 SVIT-v1.5 在多个基准上超越最先进的多模态大型语言模型,使用新的 coreset 数据配方以及全量和 LoRA 微调。
Thanks to the emerging of foundation models, the large language and vision models are integrated to acquire the multimodal ability of visual captioning, question answering, etc. Although existing multimodal models present impressive performance of visual understanding and reasoning, their limits are still largely under-explored due to the scarcity of high-quality instruction tuning data. To push the limits of multimodal capability, we Scale up Visual Instruction Tuning (SVIT) by constructing a dataset of 4.2 million visual instruction tuning data including 1.6M conversation question-answer (QA) pairs, 1.6M complex reasoning QA pairs, 1.0M referring QA pairs and 106K detailed image descriptions. Besides the volume, the proposed dataset is also featured by the high quality and rich diversity, which is generated by prompting GPT-4 with the abundant manual annotations of images. We also propose a new data recipe to select subset with better diversity and balance, which evokes model's superior capabilities. Extensive experiments verify that SVIT-v1.5, trained on the proposed dataset, outperforms state-of-the-art Multimodal Large Language Models on popular benchmarks. The data and code are publicly available at https://github.com/BAAI-DCAI/Visual-Instruction-Tuning.
研究动机与目标
- 推动扩大视觉指令微调,以克服多模态模型中的数据稀缺问题。
- 通过 GPT-4 提示生成一个基于 VG/COCO 的大规模、多样化、高质量 指令数据集。
- 提出数据优先于模型的策略,包括用于多样性和均衡性的 coreset 选择。
- 证明 SVIT-v1.5 在标准基准上优于现有的多模态模型。
提出的方法
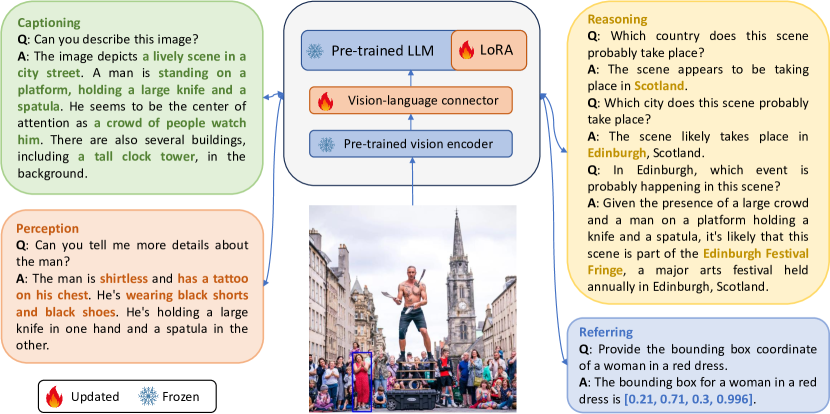
- 从 Visual Genome 和 COCO 构建 SVIT,结合丰富注释和 GPT-4 提示生成四类任务:对话问答、复杂推理问答、指代问答,以及详细图像描述。
- 使用两阶段训练流程:在冻结视觉编码器和大型语言模型的同时,对图像-文本对进行视觉语言连接器的预训练,然后对连接器和语言模型(全量或 LoRA)在视觉指令数据上进行微调。
- 引入 SVIT-core-150K 作为面向多样性和均衡的核心集,通过 GPT-4 驱动的概念重叠过滤器与 Yes/No 平衡调整实现。
- 通过用 SVIT-core-150K 替换部分先前数据(如 LLaVA-Instruct-150K)构建 SVIT-mix-665K 以测试数据效率,并扩展到 SVIT-train 以获得更大的收益。
实验结果
研究问题
- RQ1扩大高质量视觉指令数据规模如何影响多模态模型在标准基准上的表现?
- RQ2是否存在一个关注多样性和均衡性的数据子集(核心集)能提升指令微调的效率和效果?
- RQ3在用 SVIT 数据训练时,全参数微调与 LoRA 微调各自有何提升?
- RQ4增加数据量(SVIT-train)是否在感知和认知任务上带来一致的改进?
主要发现
- SVIT-v1.5 (Full) 在大多数基准上优于 LLaVA-v1.5 和其他模型,在 MME 感知与认知方面获得显著提升。
- SVIT-v1.5 (LoRA) 超过 LLaVA-v1.5 (LoRA) 在 MME 认知方面,展现了高效微调的显著收益。
- 以多样性为聚焦的 SVIT-80K-D 相比随机选择的 SVIT-80K 提升了 20.3 点。
- 在训练数据中平衡 Yes/No 问题(SVIT-80K-B)使 MME 的提升比 SVIT-80K 高出 7.1%。
- 扩大 SVIT-train(更大数据)使总 MME 分数相对于 SVIT-80K 提升 +12.7%,在对象存在性、颜色和 OCR 任务上有显著收益。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。