[论文解读] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
SweetDreamer 将二维扩散几何先验与粗糙的三维几何对齐,以实现3D一致的文本到3D结果,从而在现有流水线中实现无缝集成,达到最先进的一致性。
It is inherently ambiguous to lift 2D results from pre-trained diffusion models to a 3D world for text-to-3D generation. 2D diffusion models solely learn view-agnostic priors and thus lack 3D knowledge during the lifting, leading to the multi-view inconsistency problem. We find that this problem primarily stems from geometric inconsistency, and avoiding misplaced geometric structures substantially mitigates the problem in the final outputs. Therefore, we improve the consistency by aligning the 2D geometric priors in diffusion models with well-defined 3D shapes during the lifting, addressing the vast majority of the problem. This is achieved by fine-tuning the 2D diffusion model to be viewpoint-aware and to produce view-specific coordinate maps of canonically oriented 3D objects. In our process, only coarse 3D information is used for aligning. This "coarse" alignment not only resolves the multi-view inconsistency in geometries but also retains the ability in 2D diffusion models to generate detailed and diversified high-quality objects unseen in the 3D datasets. Furthermore, our aligned geometric priors (AGP) are generic and can be seamlessly integrated into various state-of-the-art pipelines, obtaining high generalizability in terms of unseen shapes and visual appearance while greatly alleviating the multi-view inconsistency problem. Our method represents a new state-of-the-art performance with an 85+% consistency rate by human evaluation, while many previous methods are around 30%. Our project page is https://sweetdreamer3d.github.io/
研究动机与目标
- Motivate the need to reduce multi-view inconsistency when lifting 2D diffusion results to 3D.
- Propose a method to align 2D geometric priors with canonical 3D geometries using coarse alignment.
- Show how AGP can be integrated into multiple 3D representations and pipelines.
- Demonstrate improved 3D consistency while preserving 2D diffusion generalizability.
提出的方法
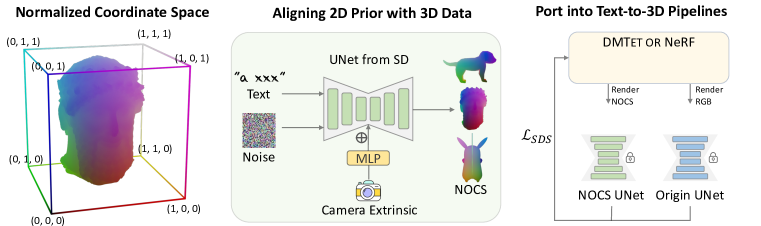
- Fine-tune a 2D diffusion model to generate viewpoint-conditioned canonical coordinates maps (CCMs) from canonically oriented 3D objects.
- Render coarse 3D depth maps to CCMs and use camera extrinsics as conditions fed through an MLP into the diffusion model.
- Use a latent-space training setup on Stable Diffusion to learn CCMs without re-encoding/decoding via VAE.
- Inject coarse 3D priors into text-to-3D pipelines to supervise geometry (SDS losses) while leaving appearance priors intact.
- Demonstrate integration with Fantasia3D (DMTet) and DreamFusion (NeRF) pipelines by adding an aligned geometry supervision term.
- Utilize Objaverse-derived data (270k objects after filtering) and coarse camera sampling to train the CCM-conditioned diffusion model.

实验结果
研究问题
- RQ1Can aligning 2D diffusion priors to canonical 3D geometries reduce multi-view inconsistency in text-to-3D lifting?
- RQ2Does coarse alignment of geometric priors preserve the diffusion model's 2D generalization while improving 3D consistency?
- RQ3How can AGP be integrated into multiple 3D representations without compromising appearance quality?
- RQ4What is the impact of camera conditioning and CCMs on 3D consistency across diverse prompts and shapes?
- RQ5How does AGP perform relative to existing baselines in human-perceived 3D consistency?
主要发现
- AGP achieves state-of-the-art 3D consistency with 85+% human-evaluated consistency rates in two pipelines.
- AGP-based methods substantially outperform baselines like DreamFusion-IF, Magic3D-IF, TextMesh-IF, SJC, and Fantasia3D in consistency.
- Training uses only coarse 3D geometry maps and avoids strong reliance on high-fidelity 3D appearance data.
- AGP is compatible with multiple 3D representations (DMTet and NeRF) and can be integrated as an additional supervision branch.
- The approach retains the rich generative capabilities of 2D diffusion models for unseen shapes and appearances.
- User studies indicate robust preference for AGP-enabled results over baselines in terms of 3D consistency.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。