[论文解读] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer 引入了带有移窗的层次化视觉 Transformer,实现线性复杂度,并在图像分类、目标检测和语义分割等任务中取得了优异的结果。
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with extbf{S}hifted extbf{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures. The code and models are publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
研究动机与目标
- 开发一个用于视觉的通用 Transformer 主干,能够处理多尺度的视觉实体。
- 通过局部窗口自注意力实现相对于图像大小的线性计算复杂度。
- 实现分层特征图以支持密集预测任务,并兼容 FPN/U-Net 风格。
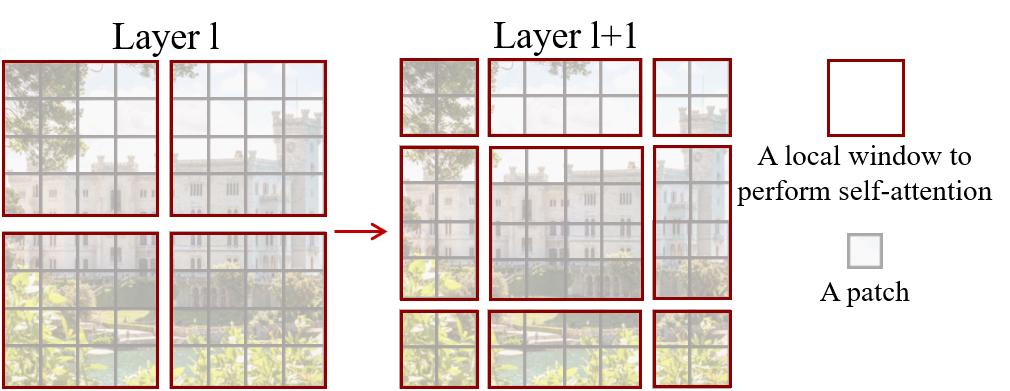
- 通过移窗分区在各层之间桥接窗口,以提升建模能力。
提出的方法
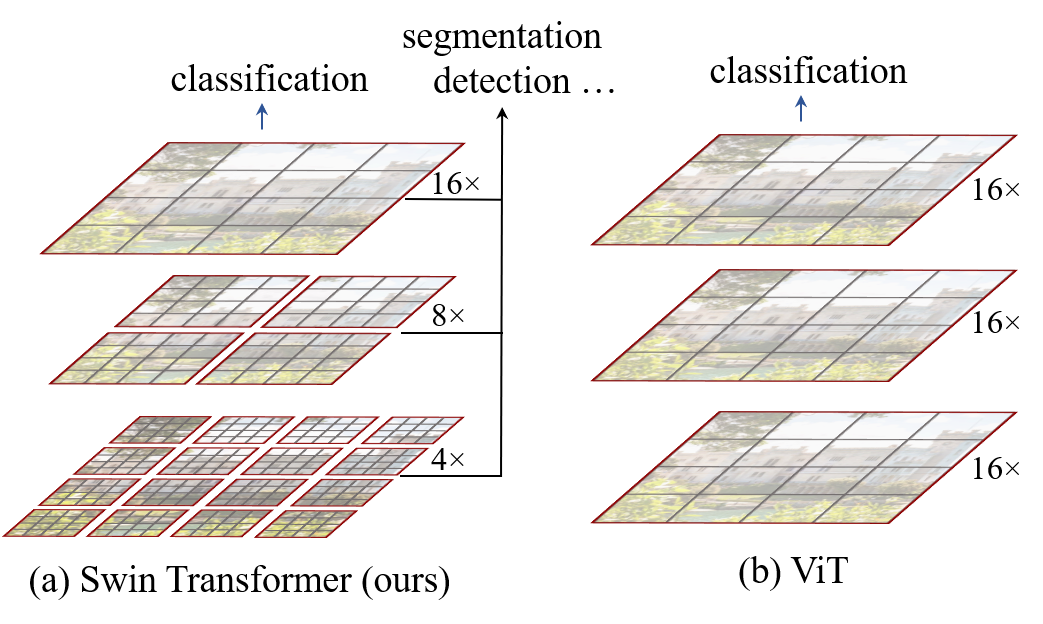
- 将图像分割成补丁令牌并线性嵌入,形成分层阶段。
- 在不重叠的窗口内局部计算自注意力,以实现线性复杂度。
- 在相邻块之间应用移窗策略,以实现跨窗口连接。
- 在自注意力中使用相对位置偏置以改进空间建模。
- 构建包含 W-MSA 与 SW-MSA 的 Swin Transformer 块,随后是带 GELU 的 MLP 与残差连接。
- 提供多种模型尺寸(Swin-T/Swin-S/Swin-B/Swin-L),并给出各阶段的配置。
实验结果
研究问题
- RQ1具有移窗自注意力的分层 Transformer 能否作为分类与密集视觉任务的通用骨干网络?
- RQ2在层之间移动窗口分区是否能提供跨窗口连接且延迟在可接受范围内?
- RQ3相较于最先进的骨干网络,Swin Transformer 在 ImageNet-1K、COCO 目标检测/实例分割以及 ADE20K 语义分割上的表现如何?
主要发现
- Swin-T 在 ImageNet-1K 常规训练下达到 81.3% 的 top-1,并且在 ImageNet-22K 预训练下,Swin-B/L 分别达到 86.4%/87.3%。
- 在 COCO test-dev 上,Swin-T/B-L 超越先前的最先进结果,箱 AP 最高提升至 +2.7,掩码 AP 提升至 +2.6。
- 在 ADE20K 验证集上,Swin-S/L 分别比先前最佳模型提升 +5.3 mIoU 和 +3.2 mIoU。
- Swin Transformer 在分类、检测和分割任务上,与具有相似延迟的 DeiT 和 ResNeXt/ResNet 骨干相比显著优越。
- 移窗设计在建模能力上提供显著提升,且延迟开销仅为适度,同时相对位置偏置在各任务上提升性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。