[论文解读] Swin Transformer V2: Scaling Up Capacity and Resolution
本文将 Swin Transformer 扩展到 3B 参数和 1,536×1,536 图像,使用残差后归一化、缩放余弦注意力、对数间隔的连续位置偏置,并辅以自监督预训练,在若干视觉任务上达到最先进水平。
Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536$ imes$1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time. Code is available at \url{https://github.com/microsoft/Swin-Transformer}.
研究动机与目标
- 激励扩展视觉变换器以缩小与语言模型之间的容量差距。
- 解决在扩大模型容量时出现的训练不稳定性。
- 弥合预训练和微调之间在高分辨率输入上的分辨率差距。
- 通过自监督预训练减少对大规模有标签数据的依赖。
提出的方法
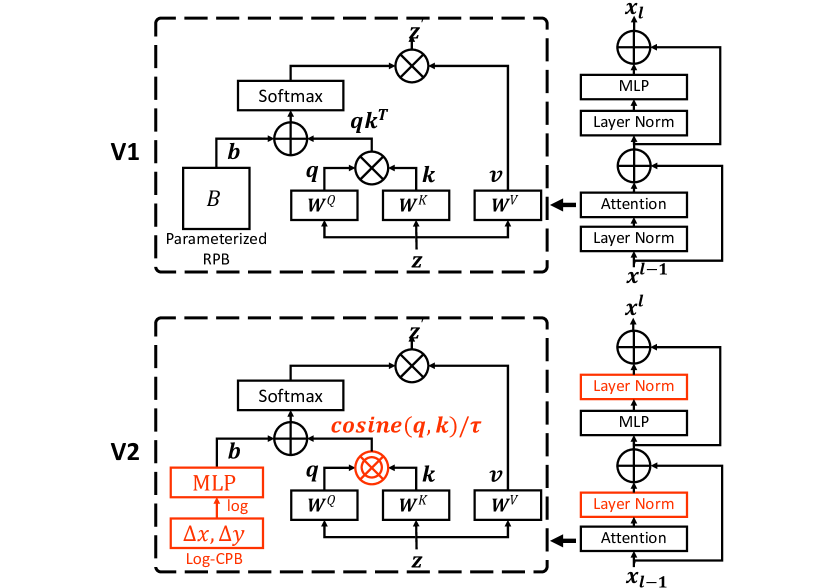
- 引入残差后归一化(res-post-norm)以通过在合并回主分支前对残差输出进行归一化来稳定训练。
- 用缩放余弦注意力替代点乘注意力,以减轻大模型中的极端注意力值。
- 提出对数间距的连续位置偏置(Log-CPB),由一个小型元网络生成,使其能够跨不同窗口大小进行迁移。
- 使用自监督预训练(SimMIM)以降低对带标签数据的依赖,从而实现非常大模型的训练。
- 应用记忆与计算节省技术(ZeRO、激活检查点、序列化自注意力)以在高分辨率下训练高达 3B 参数。
实验结果
研究问题
- RQ1如何在保持训练稳定性的同时将视觉变换器扩展到十亿级参数?
- RQ2如何使预训练在不同输入分辨率和窗口大小之间具有可迁移性?
- RQ3自监督预训练是否能降低大视觉模型对带标签数据的需求?
- RQ4哪些架构与优化策略的组合能够在高分辨率图像上高效训练大型视觉骨干网络?
主要发现
- 一个拥有 3B 参数的 Swin Transformer V2 在多个视觉任务上取得了最先进的结果:ImageNet-V2 的 top-1 84.0%,COCO 目标检测的 63.1/54.4(框/mask AP),ADE20K 的 59.9 mIoU,以及 Kinetics-400 的 top-1 86.8%。
- Res-post-norm 和缩放的余弦注意力提高了稳定性和准确性,特别是在较大模型中。
- 对数间距的连续位置偏置使跨窗口大小的有效迁移成为可能(用较小窗口进行预训练,在较大窗口上进行微调)。
- 使用 SimMIM 的自监督预训练在显著更少的带标记数据条件下实现了强劲的性能(使用了 70M 标记图像,而先前的工作使用的标记数据多出约 40 倍)。
- 内存与计算节省策略(ZeRO、激活检查点、序列化自注意力)使在 1,536×1,536 分辨率下对大型模型进行训练成为可能。
![Figure 2 : The Signal Propagation Plot [ 76 , 6 ] for various model sizes. H-size models are trained at a self-supervised learning phase, and other sizes are trained by an image classification task. * indicates that we use a 40-epoch model before it crashes.](https://ar5iv.labs.arxiv.org/html/2111.09883/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。